はじめに
株式会社QualiArtsでバックエンドエンジニアを担当している島田です。 2021年6月リリースの「IDOLY PRIDE」(以降、アイプラ)の開発に携わり、Google Cloud Spanner(以降、Spanner)の導入や基盤開発を担当しました。 本記事では、Spannerをどのように活用しているか、また使用してみて良かった点・苦労した点についてまとめます。
Spannerとは
SpannerはGoogleによって開発され、2017年にGoogle Cloud Platform(以降、GCP)上で公開されたデータベースです。以下のような特徴があります。
- グローバルなスケーラビリティ
- リージョンや大陸を跨いだ水平スケールが可能、ノードを増やせば増やすほどスループットが向上する
- フルマネージド
- ユーザー側で設定するのは基本的にリージョンとノード数のみ
- スキーマ、ACID トランザクション、SQL クエリ
- 従来のRDBと同様に利用可能で強整合性を持つ
QualiArtsではこれまで、メインのデータベースとしてMySQLやMongoDBを採用してきました。 MySQLのスキーマやトランザクションによる整合性とMongoDBのスケール性のメリットを併せ持ち、かつフルマネージドというSpannerの特徴に魅力を感じ、事前に性能検証や周辺環境の調査を行った上で採用に至りました。
活用方法
本章では、アイプラでどのようにSpannerを活用しているかを紹介します。
自動生成
アイプラではサーバーの言語としてGoを採用しており、Googleが提供する公式のSpannerクライアントを利用しています。カスタマイズ性の観点から他のサードパーティ製のパッケージは利用せず、SpannerのINFORMATION_SCHEMAを元に1テーブルにつき以下の4種類のコードを独自に生成しています。
- Entity
- Repository
- QueryBuilder
- Cache
以下で詳細を説明していきます。
Entity
テーブルのレコードに対応する構造体やスキーマ情報を保持するデータを生成しています。
type User struct {
UserID string `json:"UserID,omitempty"`
Name string `json:"Name,omitempty"`
Level int64 `json:"Level,omitempty"`
CreatedAt time.Time `json:"CreatedAt,omitempty"`
UpdatedAt time.Time `json:"UpdatedAt,omitempty"`
}
type Users []*User
var (
Table = "User"
Columns = struct {
UserID string
Name string
Level string
CreatedAt string
UpdatedAt string
}{
UserID: "UserID",
Name: "Name",
Level: "Level",
CreatedAt: "CreatedAt",
UpdatedAt: "UpdatedAt",
}
Cols = []string{
Columns.UserID,
Columns.Name,
Columns.Level,
Columns.CreatedAt,
Columns.UpdatedAt,
}
PKCols = []string{
Columns.UserID,
}
)他にも、インデックスの情報やコレクション操作のメソッド等を生成しています。
Repository
テーブルに対する基本的な各種操作を担います。
type Repository interface {
// PK指定でのレコード検索(該当のレコードが存在しない場合はエラー)
LoadByPK(ctx context.Context, userTx database.UserTx, key *entity.PK) (*entity.User, error)
// PK指定でのレコード検索
SelectByPK(ctx context.Context, userTx database.UserTx, key *entity.PK) (*entity.User, error)
// 複数PK指定でのレコード検索
SelectByPKs(ctx context.Context, userTx database.UserTx, keys entity.PKs) (entity.Users, error)
// レコードの挿入
Insert(ctx context.Context, userTx database.UserTx, e *entity.User) error
// レコードの更新
Update(ctx context.Context, userTx database.UserTx, e *entity.User) error
// カラム指定でのレコードの更新
UpdateBySelective(ctx context.Context, userTx database.UserTx, e *entity.User, updateColumns ...entity.ColumnName) error
// レコードの挿入 or 更新 (UPSERT)
Save(ctx context.Context, userTx database.UserTx, e *entity.User) error
// PK指定でのレコードの削除
Delete(ctx context.Context, userTx database.UserTx, key *entity.PK) error
// Entity指定でのレコードの削除
DeleteByEntity(ctx context.Context, userTx database.UserTx, e *entity.User) error
}また、テーブルにインデックスが存在する場合は、上述のメソッドに加えて専用の検索メソッドを生成しています。 Repositoryの実装については、少し長くなるので割愛させていただきます。
QueryBuilder
Repositoryで生成される基本的なDB操作以外の処理を行いたい場合に、QueryBuilderを用いてSQLを構築します。
type QueryBuilder struct {
builder strings.Builder
params map[string]interface{}
paramIndex int
conditions []*condition
}以下がQueryBuilderの使用イメージです。
// SELECT col1, col2, ... FROM User WHERE Level = @level AND UpdatedAt > @updatedAt
query := NewQueryBuilder().SelectAll().Where().LevelEq(level).And().UpdatedAtGt(updatedAt).GetQuery()Cache
リクエスト単位でSELECTクエリ結果をキャッシュしておく仕組みです。
// キャッシュされたデータ
type cache struct {
value *user.User
}
// クエリ単位での検索条件
type query struct {
conditions []*condition
}
// 単一の検索条件
type condition struct {
column string
operator ConditionOperator
value interface{}
}
// キャッシュ管理構造体
type cacher struct {
sync.RWMutex
queries []*query
caches map[string]*cache
}クエリ結果を保存した上記のcacherをGoのContextに格納しておくことで実現しており、UPDATEやDELETEクエリが実行された場合はキャッシュ内容の更新も行っています。自動生成したRepository内でキャッシュの取得や更新の処理を行っているので、開発者が実装時に意識する必要はありません。
また、同じテーブルに対して複数回検索が発生するような処理では、事前にまとめて検索を行いキャッシュしておくことで、Spannerへの検索回数を削減する工夫をしています。
マイグレーション
マイグレーションには、Go製マイグレーションツールの golang-migrate を利用しています。 以下のようにGoのライブラリとしても利用することができるので、アイプラではいくつかの前処理を行った上でDDLを適用する形で実装しています。
import (
"fmt"
"log"
"os"
"github.com/golang-migrate/migrate/v4"
_ "github.com/golang-migrate/migrate/v4/database/spanner"
_ "github.com/golang-migrate/migrate/v4/source/file"
)
func main() {
sourceURL := "file://ddl/spanner"
spannerURL := fmt.Sprintf(
"spanner://projects/%s/instances/%s/databases/%s?x-clean-statements=true",
os.Getenv("SPANNER_PROJECT_ID"),
os.Getenv("SPANNER_INSTANCE"),
os.Getenv("SPANNER_DB"),
)
m, err := migrate.New(sourceURL, spannerURL)
if err != nil {
log.Fatal(err)
}
if err := m.Up(); err != nil {
log.Fatal(err)
}
}また、golang-migrateはSpanner以外にも様々なデータベースに対応しています。 アイプラではマスタデータの管理等にMySQLも使用しているので、MySQLのマイグレーションについても同様にgolang-migrateで実装しています。
Kubernetesとの連携
アイプラではコンピューティングリソースにGKEを利用しています。
負荷の集中する時間帯には偏りが有るため、kubebuilderを利用してKubernetesのカスタムリソースを作成し、Spannerのノード数を時間帯に応じて最適化しています。
また、KubernetesのCronJobリソースを利用して、gcloud spanner backups createコマンドを定期実行し、一定間隔でバックアップを取得するようにしています。
containers:
- name: spanner-backup
image: google/cloud-sdk:alpine
imagePullPolicy: IfNotPresent
command:
- "/bin/sh"
- "-c"
args:
- |
gcloud spanner backups create \
{{ .Values.database }}_$(date "+%Y%m%d%H%M%S") \
--project={{ .Values.project }} \
--instance={{ .Values.instance }} \
--database={{ .Values.database }} \
--retention-period={{ .Values.retentionPeriod }} \
--async良かった点
本章では、Spannerを運用してみて良かった点について述べます。
安定したパフォーマンス
水平スケールを自前で考慮することなく安定したパフォーマンスを発揮してくれています。
Spannerはデータサイズや負荷に応じて、物理的にデータを分割して配置します。この分割されたデータのまとまりのことをスプリットと言います。Spannerが十分なパフォーマンスを発揮するためには、主キーカラムに連続性のある値を指定しない等のホットスポット(特定のスプリットへの負荷の偏り)が生じない設計が必要です。
また、レイテンシが小さいわけではないので、APIとしてのレスポンスタイムが大きくならないように、並列で検索を行う等の工夫はしています。
スケールの容易性
GCPコンソールから変更したい数値を指定するだけでノード数(もしくはプロセッシングユニット数)が簡単に調整できます。アイプラではインフラ管理にTerraformを使用していますが、その場合もnum_nodes(もしくはprocessing_units)の値で設定できます。ダウンタイムなく適用できるのも大きな魅力で、そのおかげで柔軟なノード数調整が可能です。
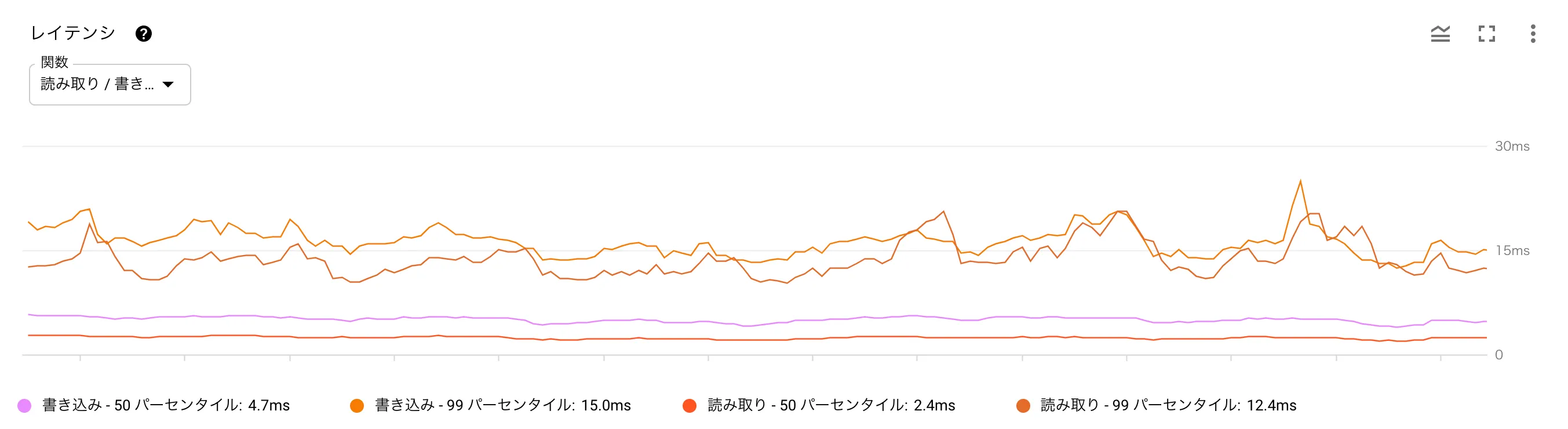
時間帯に応じてノード数を調整していると前述しましたが、以下はデイリーのノード数の変化とレイテンシ・CPU使用率のグラフとなります。ノード数を調整したタイミングでも、レイテンシやCPU使用率が増加していないことがお分かりいただけるかと思います。(深夜帯に少しレイテンシが増加していますがバッチ実行の影響です)
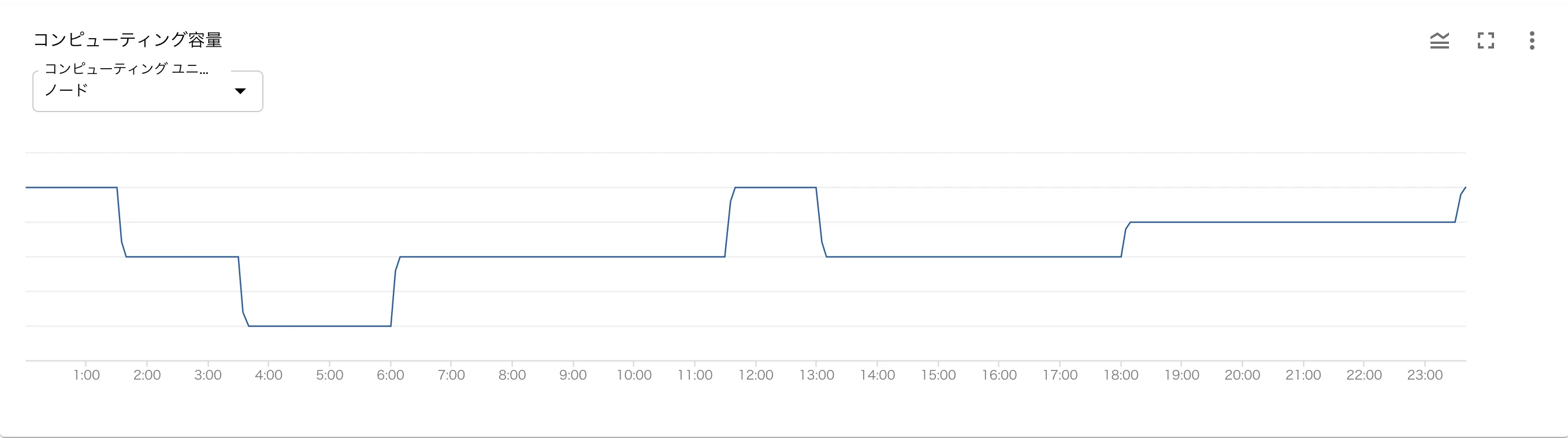
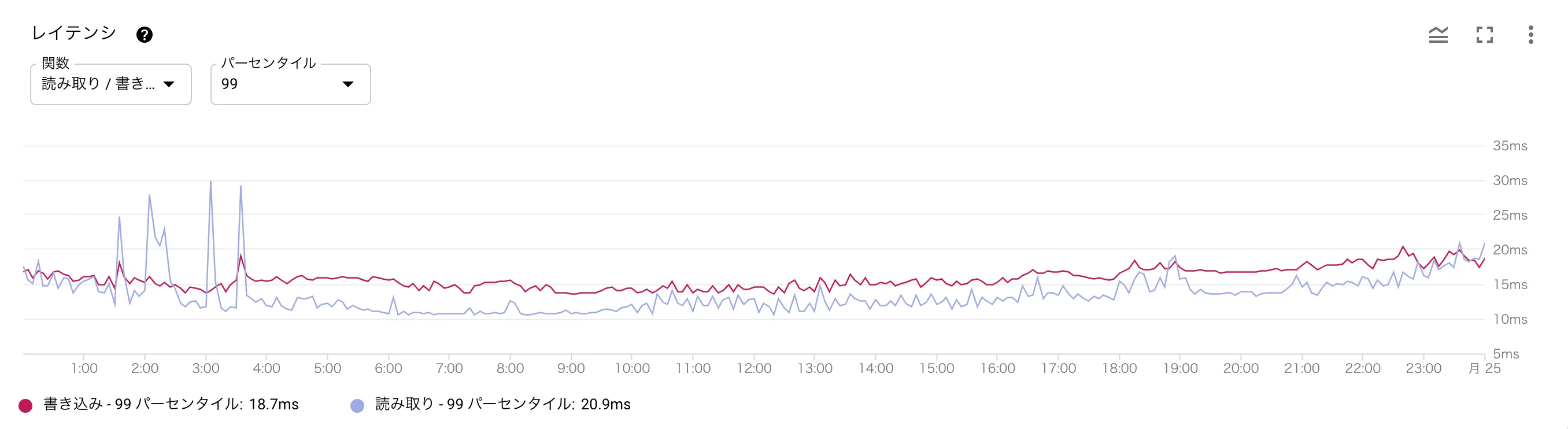
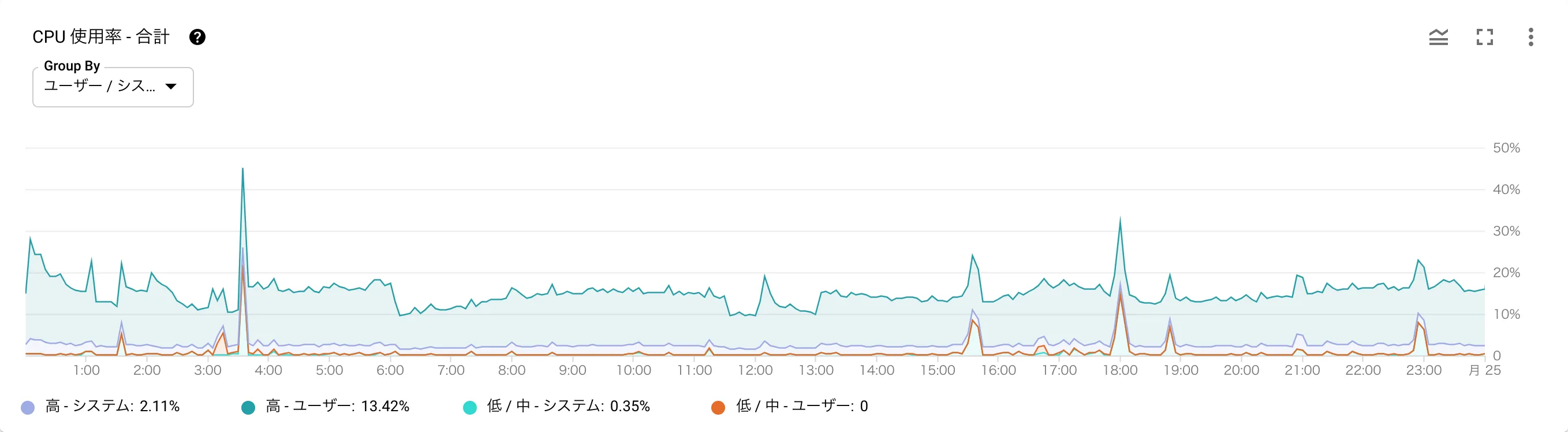
Spanner導入時の懸念点としてコストの高さがありましたが、このように柔軟にノード数の調整が可能となるので、当初の見積もりよりもコストがかなり抑えられています。
また、基本的にCPUをメインに監視すれば良いという点もシンプルです。
周辺環境の充実
エミュレータの提供
アイプラの開発初期はエミュレータが存在せず、ローカルでのAPI起動やSpannerを用いるテストにおいて、GCP上のSpannerインスタンスに個人単位でデータベースを作成して接続していました。エミュレータの登場以降は、各個人開発作業はローカルで完結するようになりました。
最低処理コンピューティングの変更
設定できる最低処理コンピューティングが1ノードから100プロセッシングユニット(1ノード = 1000プロセッシングユニット)となりました。これにより、開発環境等の1ノードではオーバースペックだった環境で適切なコンピューティングリソースの調整が可能となったため、より低コストでSpannerを運用することが可能となりました。
その他にもここ1,2年程で、
- 各種統計情報の取得
- バックアップ
- キービジュアライザー
- レコードのTTL
等の多数のアップデートが登場しています。今後も周辺環境が充実し、より便利にSpannerが利用できることが期待できます。
苦労した点
本章では、Spannerを使用する上で苦労した点について述べます。
ミューテーションの上限
Spannerでは1つのトランザクションで更新できるのが20000ミューテーションまでという制限があります。 ミューテーションとは、表計算ソフトで言うところのセルのようなイメージです。
例えば、3カラムのテーブルに2レコードを挿入する場合は6ミューテーションとなります。
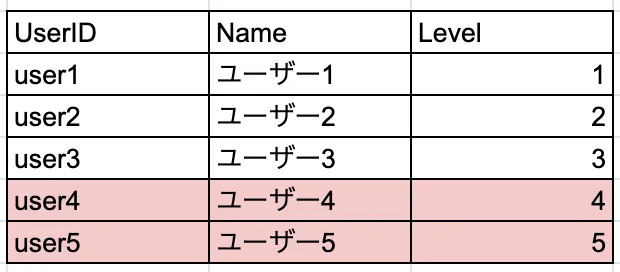
厳密にはインデックス等も関係してくるのでもう少し複雑です。ミューテーション数の制約がないPartitionedUpdateという方法も提供されているのですが、Insertに対応していない等の制約があるため、すべてのケースで利用できるわけではありません。
そのためバッチ処理等の一括での更新が必要になる場面では、一定単位で更新対象のレコードを分割してトランザクションを複数実行する対応をしています。
単一レコードの同時更新
Spannerクライアントには、トランザクションが失敗した際にトランザクションメソッドに渡した関数単位でリトライを行う機構が組み込まれています。 リトライはトランザクションメソッドに渡した関数単位で行われます。
f := func(ctx context.Context, txn *spannerReadWriteTransaction) error {
stmt := spanner.Statement{
SQL: `INSERT User (UserID, Name, Level) VALUES
("UserID1", "ユーザー1", 1),
("UserID2", "ユーザー2", 2),
("UserID3", "ユーザー3", 3)`,
}
_, err := txn.Update(ctx, stmt)
return err
}
// リトライ時には関数fが再度実行される
_, err := client.ReadWriteTransaction(ctx, f)複数のトランザクションで一つのレコードに対して操作を行うと、一方のトランザクションが失敗し、失敗したトランザクションではリトライが発生します。そのため、ギルドやグループのデータのように単一のレコードを複数人で更新する場合、リトライが頻発しAPIのパフォーマンス低下に繋がります。
アイプラでは、複数ユーザーが更新するデータについてはRedisで管理するようにし、リトライ自体が発生しないようにしました。また一部の処理においては、メインのトランザクション中でContextに値を詰めておき、必要に応じて別のトランザクションで処理を行うことでリトライ時の影響範囲が小さくなるような対応をしています。
type spannerTxManager struct {
client *spanner.Client
}
func (m *spannerTxManager) Transaction(ctx context.Context, f func(ctx context.Context, tx *spanner.ReadWriteTransaction) error) error {
// メインのトランザクション
if _, err := m.client.ReadWriteTransaction(ctx, func(ctx context.Context, tx *spanner.ReadWriteTransaction) error {
return nil
}); err != nil {
return err
}
// Contextから取り出した値に応じて別のトランザクションを実行
if isXxx {
// 一部の処理でのみ実行されるトランザクション
_, _ := m.client.ReadWriteTransaction(ctx, func(ctx context.Context, tx *spanner.ReadWriteTransaction) error {
return nil
})
}
return nil
}トランザクションのリトライ
トランザクションのリトライは、レコードの同時更新以外でも様々な要因で発生するとされています。
前述のとおり、一つのトランザクション処理が長いとリトライのコストが高くなりパフォーマンス悪化に繋がるので、ロックを獲得しないReadOnlyTransactionをメインで使用し、書き込みを行うタイミングのみReadWriteTransactionを使用することで、トランザクションができるだけ短くなるように工夫しています。
また、冪等性を考慮した実装も必要となります。 外部リソースの操作やログ出力等のトランザクションの成功時に実行したい処理については、トランザクション中ではContextに情報を詰めつつ、トランザクション完了後に処理を実行、リトライ時は各種リセット処理を挟むことによって対応しています。
func (m *spannerTxManager) Transaction(ctx context.Context, f func(ctx context.Context, tx *spanner.ReadWriteTransaction) error) error {
var retryCount int32
_, err := m.client.ReadWriteTransaction(ctx, func(ctx context.Context, tx *spanner.ReadWriteTransaction) error {
if retryCount > 0 {
// 各種リセット処理
}
retryCount++
if err := f(ctx, tx); err != nil {
return err
}
return nil
})
if err != nil {
return err
}
// トランザクション成功時の処理
return nil
}ウォームアップ
Spannerをサービスインする際、スプリットが十分に分割されていないとパフォーマンスが出ません。そこで、予めスプリットを分割させるためのウォームアップを実施する必要があります。特に、ゲームのようなリリース直後にアクセス数がスパイクするようなユースケースでは、データベースのパフォーマンス低下は致命的です。
スプリットは負荷ベース、もしくは容量ベースで分割されます。また、ウォームアップはリリースの2日前に実施することが推奨されています。 アイプラでは、データの投入と全削除を行うCLIを作成し、リリース後2,3日で到達するであろう数のレコードを投入、2日間寝かせてデータの全削除行うといったフローを、負荷試験やサービス開始前に実施しました。
ウォームアップの詳細については、以下のドキュメントをご覧ください。
ゲーム データベースとして Cloud Spanner を使用する場合のベスト プラクティス
おわりに
今回アイプラでのSpanner活用事例や良かった点・苦労した点の一部を紹介させていただきました。 リリースから4ヶ月が経ちますが、パフォーマンスやスケール・監視等、運用における快適さは非常に高いです。 独特の癖もあるのでプロジェクトの要件に合うかは検討が必要ですが、周辺環境が少しずつ整い、導入ハードルも以前に比べてかなり下がってきているので、選択肢の一つとして検討してみる価値は十分あるかと思います。 本記事が皆さまのSpanner活用において、少しでもお役に立てば幸いです。
