はじめに
株式会社QualiArtsで「IDOLY PRIDE(以降、アイプラ)」のバックエンドエンジニアチームのリーダーをしている末吉です。 主にゲームAPIの開発やインフラの運用、チームメンバーの進捗管理や開発スケジュールの策定等を担当しています。
アイプラは2021年6月にリリースされ、今年の6月に2周年を迎えました。 APIサーバーや社内管理ツール等のコンピューティングにGoogle CloudのGoogle Kubernetes Engine(以降、GKE)を使用しており、2年間その運用を支えてきました。

しかし、その中でGKEを運用していくにあたって様々な課題がありました。
本記事ではそれらの課題をどのようにバックエンドエンジニアチームで改善したのかを紹介できたらと思います。
アイプラのGKE
アイプラでは環境別にクラスタを3つに分けて運用しています。
- dev (開発環境)
- stg (ステージング環境)
- prd (本番環境)
2年間運用をしていて、チームでも下記のようなメリットを感じています。
- Kubernetesの機能であるHorizontalPodAutoscalerやClusterAutoscalerを活用した高いスケーラビリティ
- CustomResourceDefinitionによる柔軟な拡張性
課題
そんなGKEですが、チーム内で運用をしていく中でいくつか課題がありました。
- チームメンバーの入れ替わりによってGKEの有識者が減ってしまった
- アップグレード作業が煩雑化していた
- 長時間実行されるJobを停止させてアップグレード作業を行う必要があった
- セキュリティアップグレードのキャッチアップが属人化してしまっていた
1つずつ詳しく説明していきます。
1.チームメンバーの入れ替わりによってGKEの有識者が減ってしまった
アイプラをリリースしてから1年程はGKEを構築したメンバーがいたのでその方にメインでGKEの運用をしていただいていました。
しかし、運用をしていく中で体制の変更があり、今年の4月にはチーム内に有識者があまりいない状態になっていました。
また、GKEを運用するにはKubernetesの知識も必要なので学習範囲も広く、一朝一夕にはいかない課題でした。
2.アップグレード作業が煩雑化していた
GKEはセキュリティリリースも含めると更新頻度がかなり高く、現在も1~2ヶ月に1度のペースでアップグレード作業が発生しています。
元々チームでは下記のように、アップグレード作業をする際にはローカルからgcloudコマンドを実行していました。
$ gcloud container clusters upgrade $CLUSTER_NAME \
--node-pool=$NODE_POOL_NAME \
--cluster-version $VERSION \
--zone(or region) $ZONEしかし、基本的に手動実行になるので
- 作業者が誤って本番環境を更新してしまう可能性がある
- 複数ノードプールを更新する際にはその分のコマンドを叩く必要があるので大変
- ノードプールを新規に追加した時に、そのノードプールの更新を行うコマンドを叩き忘れてしまう
等の課題がありました。
3.長時間実行されるJobを停止させてアップグレード作業を行う必要があった
アイプラでは「ライブシミュレーター」と呼ばれるバッチ処理があります。こちらはレベルデザイナーがdev環境の社内管理ツールから実行しています。
用途としては「安定してスコアが取れるか」「他のカードが強くなりすぎていないか」など、次のガチャで出す新カードの効果を決める際に重要な役割を果たしています。
特徴としてはKubernetesのJobを使用しており、12~24時間と長時間Jobが実行され続けます。
この「ライブシミュレーター」なのですが、GKEにおいては
- Jobの実行中にワーカーノードのアップグレードを行うとJobが停止してしまう為、アップグレード作業日は「ライブシミュレーター」を使用する事が出来ない
- 上記に伴い、事前にバックエンドエンジニアによるアップグレード作業日と、レベルデザイナーによる「ライブシミュレーター」実行日のスケジュール調整を行う必要がある
というアップグレード作業周りの課題がありました。
4.セキュリティアップグレードのキャッチアップが属人化してしまっていた
GKEでは脆弱性が見つかると不定期に公式ドキュメントが更新されます。
こちらは私の方で公式ドキュメントを手動でチェックしていたのですが、当然私が休みだとチェックが漏れてしまうので長期的にはあまり好ましくはありません。
自動で通知する仕組みがあれば他のチームメンバーが気付く事が出来るので、属人性の解消に繋がりそうだなと考えていました。
課題に対して行った事
長期での運用を見据えた時に、上記の課題を解決するのが必要だと考えました。その為、今年から以下の改善を行いました。
1.アップグレード作業をチーム内でローテーションしてメンバーの理解度を引き上げた
冒頭にアップグレード頻度が多い事について言及しましたが、こちらをポジティブに捉えるとGKEに触れる機会が多いと考えました。
そこで、今年の4月頃からメンバー内で持ち回りでアップグレード作業をローテーションするようにしてみました。これにより、現在は私以外のメンバーのほぼ全員がアップグレード作業が出来るようになり、基本的なKubernetesの知識も身についている状態にできました。
こちらの手法を選択した理由としては2つあります。
1つ目は、全員が満遍なくGKEの面倒を見れる状態を作るのが大切だと考えているからです。
長期運用をしていく中で、チーム体制の変更は避けられません。 チームで1人のみが専任でGKEの面倒を見れる状態を作ってしまうと、その人が別のプロジェクトに移動した場合にGKEをメンテナンス出来る人がいなくなってしまうからです。
2つ目は、実際に業務で扱う方が効率的に学習できると考えているからです。 勿論、ハンズオンや勉強会でもGKEとKubernetesを学ぶ事は可能です。しかし、実際に業務で触りながら学んでいく方が知識の定着度で言うと断然高いと思っています。
例えば、KubernetesにはPodDisruptionBudget(以下、PDB)と呼ばれる機能があります。 こちらはノードのDrainやスケールインが発生した際に、設定した台数のPodを維持したまま安全にevictするために必要な機能です。 Kubernetesを使ったサービスの高可用性の実現のためによく使われます。
このPDBですが、設定する台数を誤って設定してしまうとワーカーノードプールのサージアップグレード時に意図せず時間がかかってしまいます。
例えば、2台しか立っていないPodに対して最低保証台数を80%で設定してしまうと、
- 2 * 0.8 = 1.6となり、切り上げで最低必須Pod数が2台になる。
- 稼働中Pod数と最低必須Pod数が同じになるので、Podのevictが出来なくなる。
- GKEのアップグレード中のPDB有効期間は1時間なので、1時間後にようやくPodがevictがされる。
という挙動になります。
実際にチームメンバーがアップグレード作業をした時にこの挙動にハマった事があったのですが、結果的にPDBの挙動を学ぶ良い機会になりました。
2.GKEのバージョンをTerraform管理に移行した
GKEのバージョンをTerraformで管理する事によって、
$ terraform plan
$ terraform applyを行うだけでアップグレードを行えるようになりました。複数ノードプールを更新する必要がある場合は、基本的にterraform applyするだけで自動的に行ってくれるので非常に快適です。
加えてアイプラではTerraformのマニフェストファイルをGitHubで管理しているので、事前にPullRequestを出して、他メンバーがチェックする事も可能になりました。
新規にノードプールを追加する際にもTerraformを使用しているため、必然的にアップグレードの対象から漏れてしまう事も格段に減りました。
こちらは
- google_container_clusterのmin_master_versionでマスターノードのバージョンを指定
- google_container_node_poolのversionでワーカーノードのバージョンを指定
する事により実現しています。
resource "google_container_cluster" "cluster" {
min_master_version = "1.24.13-gke.2500"
}resource "google_container_node_pool" "node_pool_a" {
version = "1.24.13-gke.2500"
}
resource "google_container_node_pool" "node_pool_b" {
version = "1.24.13-gke.2500"
}3.ノードプールを2つに分けることで、Jobを停止させずアップグレード作業をできるようにした
元々「ライブシミュレーター」は1つのワーカーノードプールのみ用意しそちらにスケジューリングをしていたのですが、こちらを2つ用意する事で解決する事ができました。
- Jobがスケジュールリングされていないノードプールを先にアップグレード
- Kubernetesマニフェストを変更し、Jobをアップグレード済みのノードプールに新しくスケジューリングするように変更する
- 実行中のJobが終了したら、後日元のノードプールをアップグレード
といった流れで、Jobを停止させずにアップグレード作業を行う事ができるようになりました。
文章だと難しいので、ここからは実行中のJobがある場合を想定して具体的に説明していきます。
まずは事前にノードプールを2つ用意します。 GKEは起動しているVMに対して料金がかかるので、Jobを実行していない間ノードが立ったままにならないように、オートスケールのmin_nodeは0台に設定することを推奨します。
resource "google_container_node_pool" "node_pool_a" {
name = "live-simulator-a"
autoscaling {
min_node_count = 0
}
}
resource "google_container_node_pool" "node_pool_b" {
name = "live-simulator-b"
autoscaling {
min_node_count = 0
}
}次に、Jobのマニフェストにlive-simulator-aにスケジューリングするように設定します。
きめ細かいスケジューリングを必要としない場合、affinityを使うのではなくnodeSelectorを使用する方が可読性が向上するのでおすすめです。
apiVersion: batch/v1
kind: Job
metadata:
name: live-simulator
spec:
template:
metadata:
name: live-simulator
spec:
# aを指定する
nodeSelector:
cloud.google.com/gke-nodepool: live-simulator-a
containers:
- name: live-simulator
image: hoge/live-simulator
imagePullPolicy: IfNotPresent
command: ["/batch"]
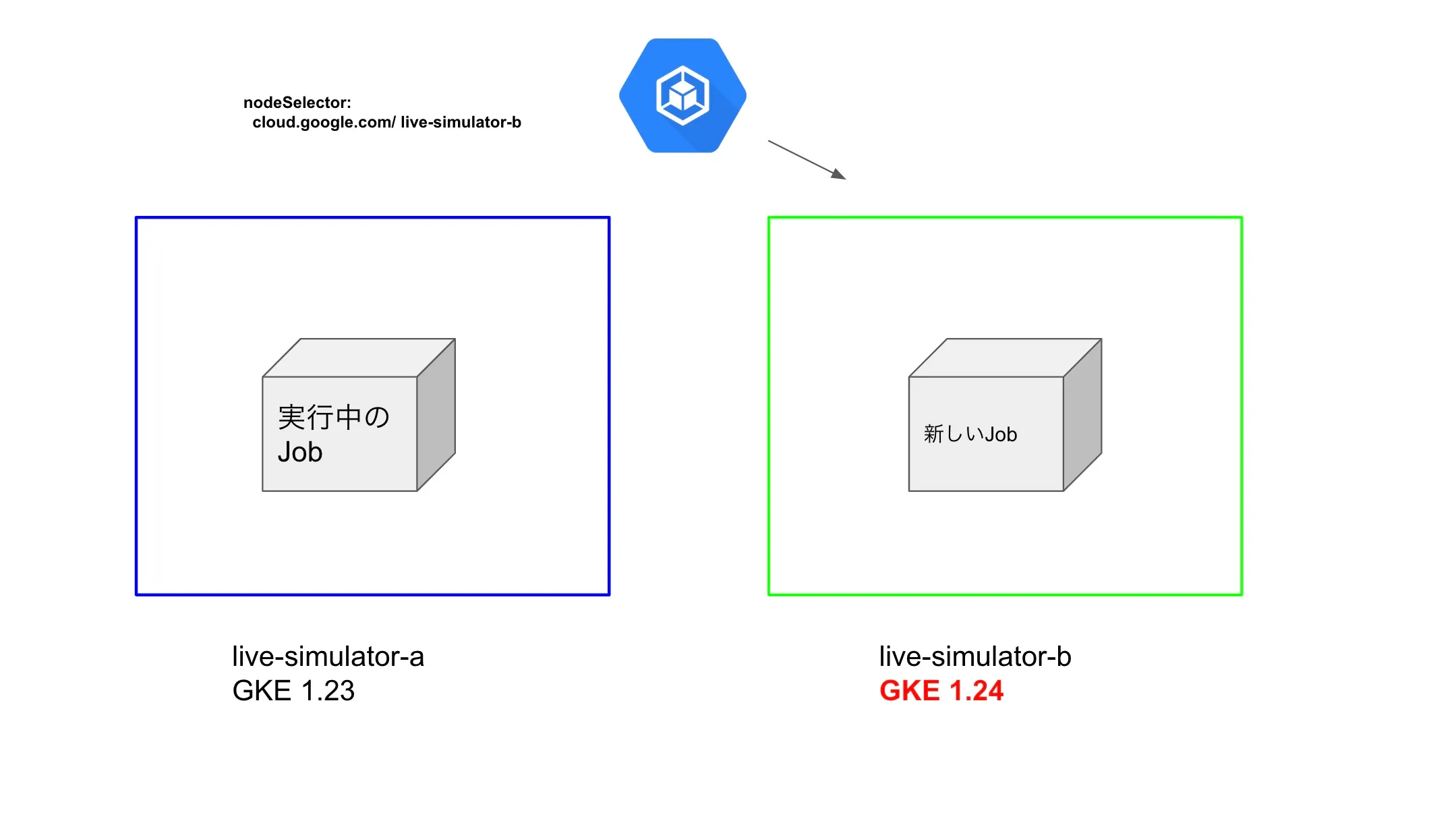
restartPolicy: Never実際にJobを実行すると下記のような状態になります。
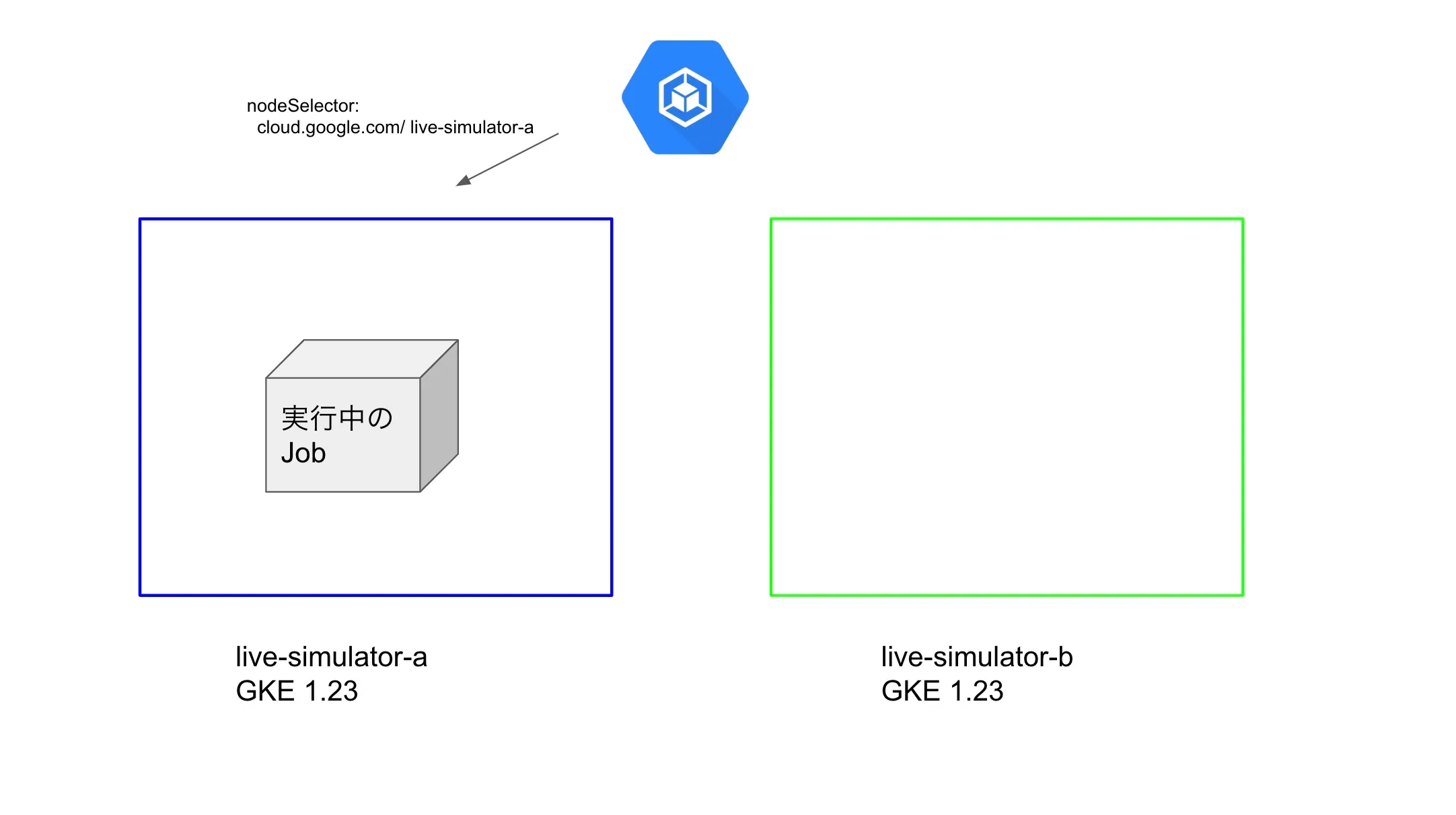
次に、Jobがスケジューリングされていないlive-simulator-bの方を先にアップグレードします。
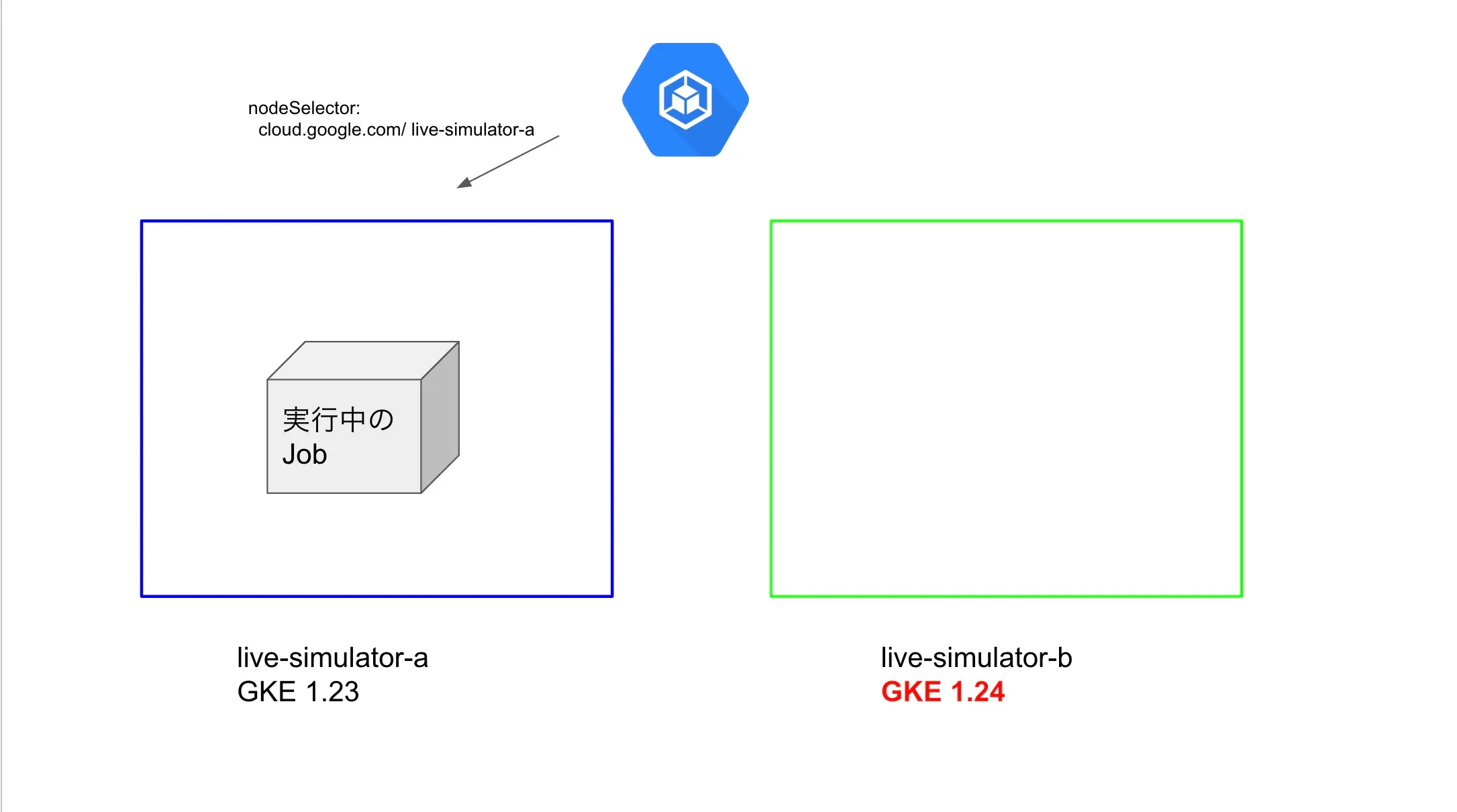
アップグレードが完了したら、JobのnodeSelectorをlive-simulator-bに書き換えて更新します。
apiVersion: batch/v1
kind: Job
metadata:
name: live-simulator
spec:
template:
metadata:
name: live-simulator
spec:
# bに変更する
nodeSelector:
cloud.google.com/gke-nodepool: live-simulator-b
containers:
- name: live-simulator
image: hoge/live-simulator
imagePullPolicy: IfNotPresent
command: ["/batch"]
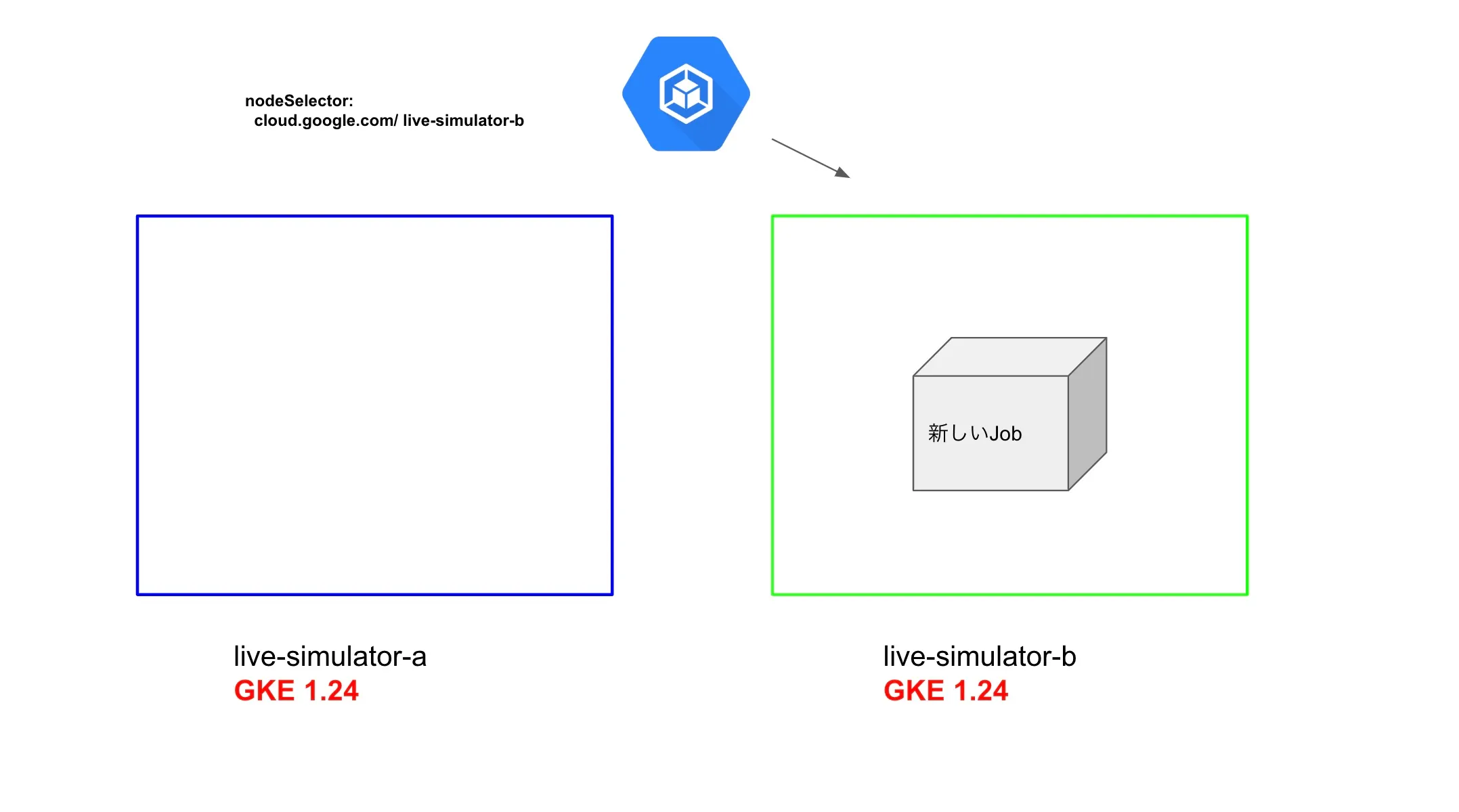
restartPolicy: Never更新すると図のような状態になります。この時点で新しくJobを実行した場合にはアップグレード済みのノードプールにスケジューリングされるようになります。
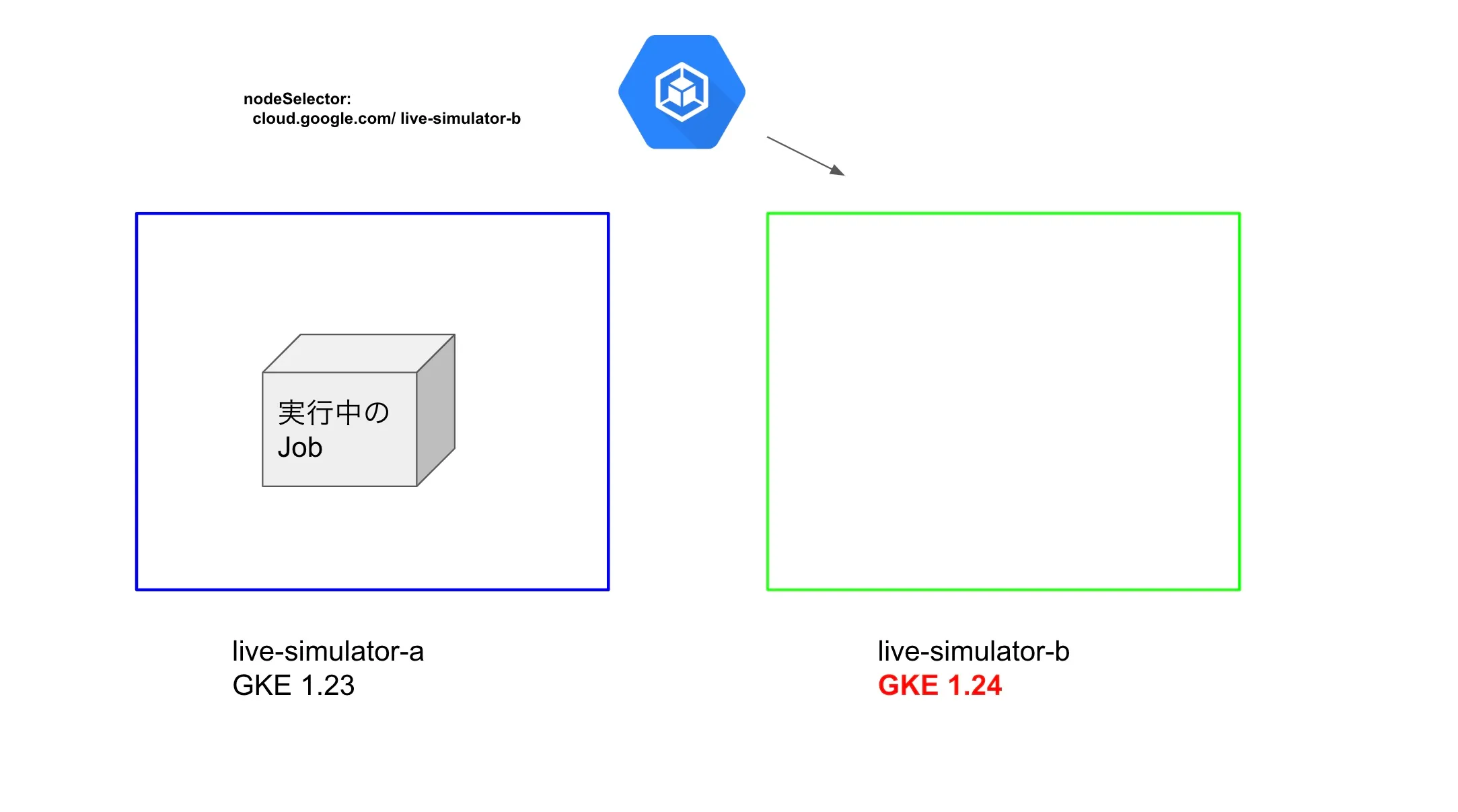
最終的に元々実行していたJobが終了したら、live-simulator-aの方もアップグレードをして作業は完了となります。
このようにノードプールを2つに分ける事によって、レベルデザイナーがGKEのアップグレード作業を気にする事なく「ライブシミュレーター」を実行できるようになりました。
また、バックエンドエンジニアとレベルデザイナー間で日程の調整をやり取りする必要がなくなり、コミュニケーションコストの削減にも繋がりました。
4.セキュリティアップグレードが更新されたらSlackに通知するようにした
公式でセキュリティアップグレードが発生した時に、下記の画像のようにSlackに投稿させるようにしました。
これにより、他のチームメンバーもセキュリティアップグレードをキャッチアップできるようになりました。
通知先をSlackにした理由ですが、弊社ではSlackをチャットコミュニケーションツールとして使用しているので、通知先としてSlackが属人性の解消に最も効果的だと考えたからです。
また、最新の情報を取得できる英語版ドキュメントの更新を通知させるようにしています。

おわりに
本記事では、アイプラのバックエンドエンジニアチームにおいてGKEをどのように運用改善してきたのか紹介しました。
アップグレード作業をローテーションする事でチームメンバーの理解度を上げる事ができたり、バージョンをTerraformで管理できるようになったり等の改善を達成できました。
本記事が皆さまの運用に少しでもお役に立てば幸いです。
