はじめに
株式会社サイバーエージェントのメディア事業の横断SREチームである「サービスリライアビリティグループ」でSREをしている鬼海 雄太です。 主にソーシャルゲームやAmebaブログなどのコミュニティサービスのインフラの設計運用、改善を担当しています。
本記事ではガールフレンド(仮)におけるデータベースの特殊なレプリケーションとその課題についてご紹介します。
3/7(木) 開催のCyberAgent Game Conference 2024で発表する以下のセッション内容の一部となります。
CAGC2024 12年目を迎えた『ガールフレンド(仮)』におけるデータベースの負債解消への道のり
ガールフレンド(仮)とは
ガールフレンド(仮)(以下GFと表記)は2012年10月にサービスを開始したWebブラウザで遊べるソーシャルゲームです。 リリースから12年目を迎え、ソーシャルゲームとしては歴史のあるサービスとなっています。

GFの構成図
まずはGFの構成を簡略化した図でご紹介します。
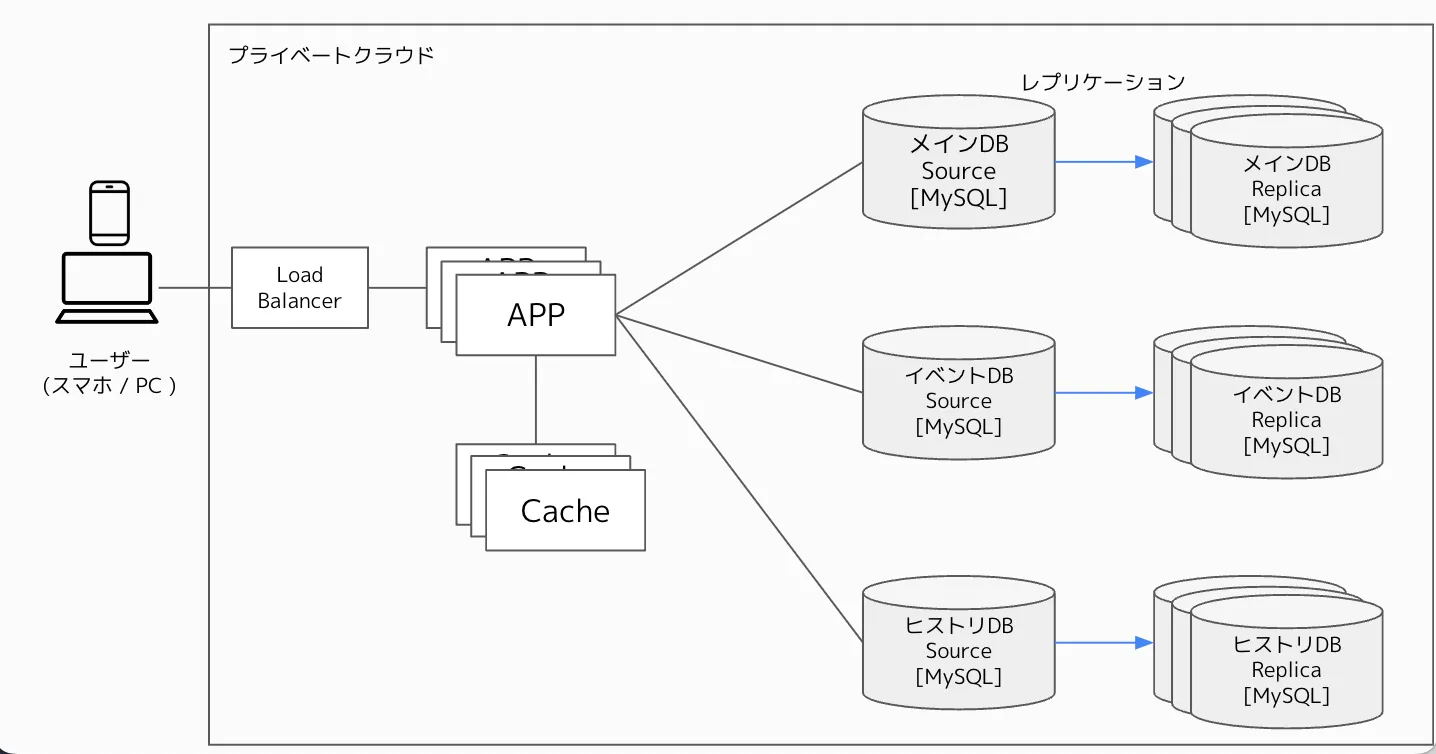
GFは弊社のプライベートクラウド上のサーバーで稼働しています。 アプリケーションサーバは仮想マシンですが、データベースサーバは物理マシンでMySQLを利用しています。
MySQLはメインDB・イベントDB・ヒストリDBの3系統に別れており、それぞれに複数台の参照用のレプリカサーバが存在しています。 構成としては非常にオーソドックスなものとなっています。
変則レプリケーション
長年運用が続いているサービスは様々な課題を抱えていることがあります。 本記事ではその課題の中から、メインDBでおこなっている特殊なレプリケーションである変則レプリケーションについてご紹介します。
変則レプリケーションとは
MySQLのソースとレプリカでレプリケーションを構成しているが、レプリカサーバごとにレプリケーションされているテーブルが異なる状態です。 この「変則レプリケーション」は正式名称ではなく、私がそう勝手に呼称しています。
正式名称では、「レプリケーションフィルタリングの機能を用いたレプリケーション」となると思いますが、このあとに紹介する話でフィルタリング機能を使用せず同様の構成を実現しており、 ややこしくなるので変則レプリケーションとして呼称させていただきます。
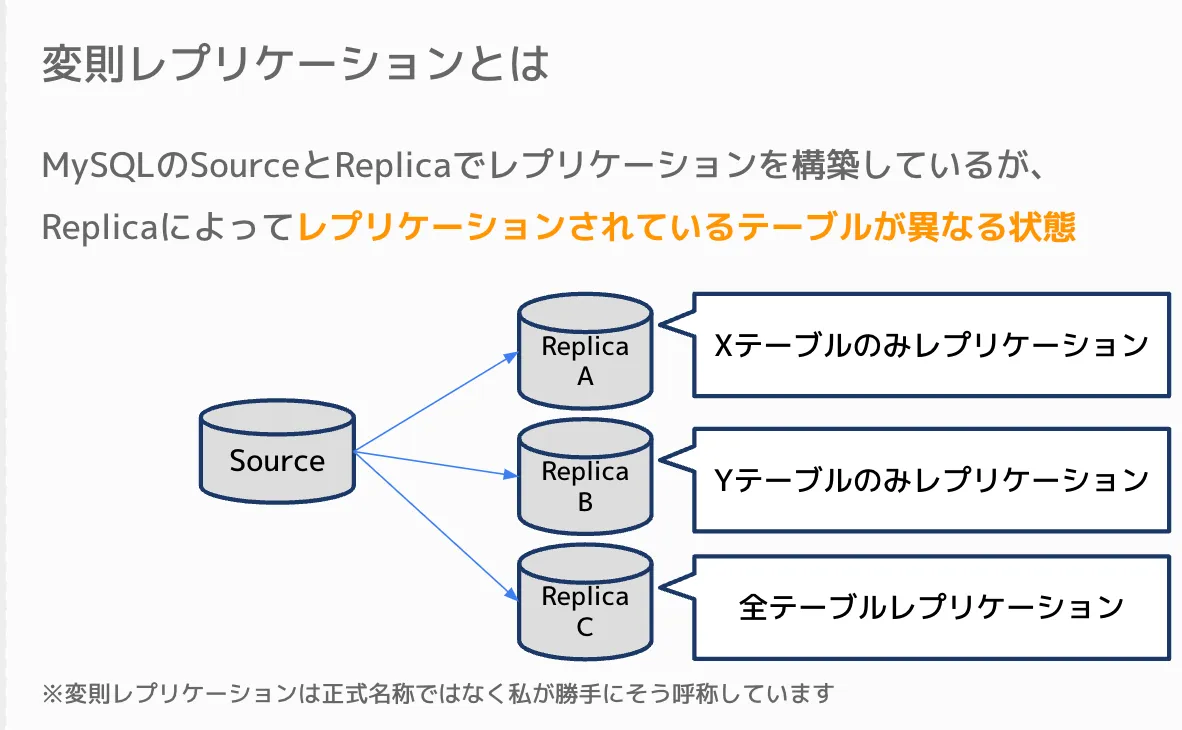
こちらの図のようにソースからレプリケーションしているレプリカA・B・Cがある状態で、 AはXテーブルのみレプリケーション、 BはYテーブルのみレプリケーション、 Cは全テーブルレプリケーション、
という状態を変則レプリケーションと呼んでいます。
レプリケーションの仕組みをおさらい
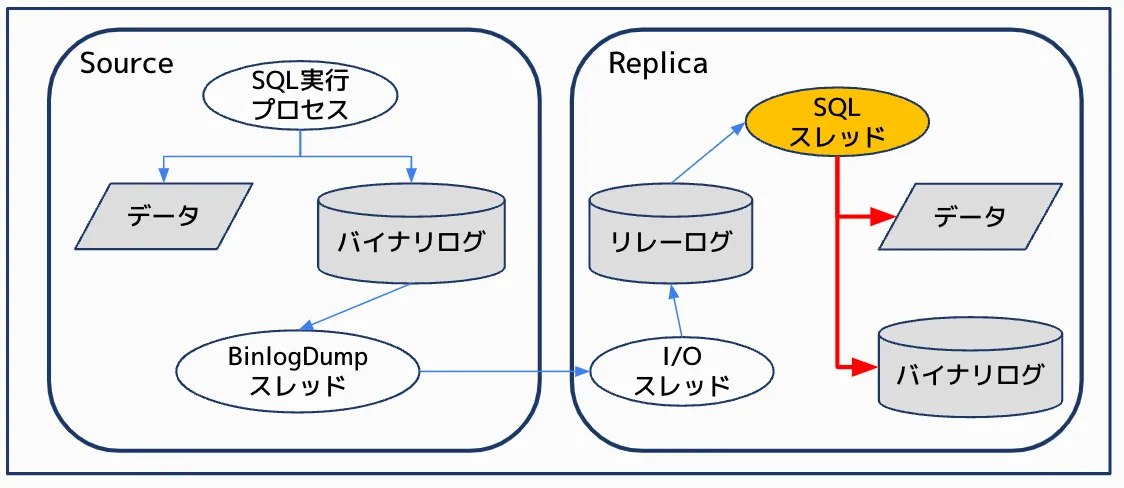
まず、MySQLのレプリケーションの仕組みを簡単にご紹介します。
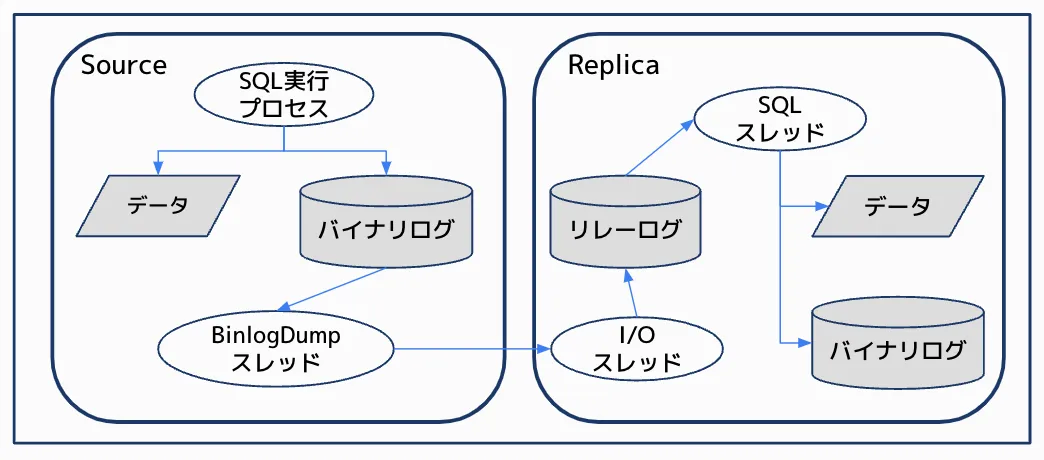
図の左側のソースDBで更新クエリが実行されると、SQL実行プロセスはデータの更新とバイナリログへの書き込みを行います。
その後、BinlogDumpスレッドがバイナリログの更新を検知し、レプリカDBにバイナリログイベントを送信します。
右側のレプリカDBでは、まずI/Oスレッドがバイナリログからイベントを受信し、リレーログと呼ばれるファイルに記録します。
そして、レプリカDBのSQLスレッドがリレーログからバイナリログイベントを取り出し、データに対してリプレイすることでレプリケーションが実現しています。
なぜ変則レプリケーションが導入されたのか
10年前の話になるのですが、2013年末から2014年の年始にかけてGFのテレビCMが放送されネット上で大いにバズりました。
その結果、ゲームのユーザー数が短期間で激増しゲーム内イベントの負荷が高騰しました。
具体的にはDBのMySQLへの書き込みクエリ数が大幅に増え、レプリカ側のレプリケーションの処理が追いつかず遅延が深刻化しました。
レプリカ側の遅延によって、ソースとレプリカ間の差分が大きくなるとゲーム進行に支障が出てしまいます。
レプリカDB上のSQLスレッドは更新を並列に処理できず、ソースDBからあまりにも大量の更新クエリが継続して送られてくるとレプリカDB上のデータ更新が追いつかない状態となってしまいます。
現在のMySQLのバージョンでは、レプリカDBのSQLスレッドを並列化できるReplica_Parallel_Workersというオプションがありますが、当時はこの設定はありませんでした。
ソースDBからの更新クエリ量を減らす根本的な解決方法としては、まずデータベース自体を分割して書き込み処理を分散させる方法があります。
しかし、これにはアプリケーション側の大幅な設計変更が必要で、すぐに対応させるのは困難でした。
レプリケーションフィルタリングによる変則レプリケーション
そこでMySQL側だけで解決できる方法として、MySQLのレプリケーションフィルタを使用する方法を採用しました。
レプリケーションフィルタはレプリケートするテーブルを制御し、レプリカDB側の処理量を減らすことが可能です。
レプリカ側のMySQLで以下の設定を有効化します。
- replicate-do-table : レプリケートするテーブルを指定
- replicate-ignore-table : レプリケートを除外するテーブルを指定 この設定を利用し下記の図のような構成をつくりました。
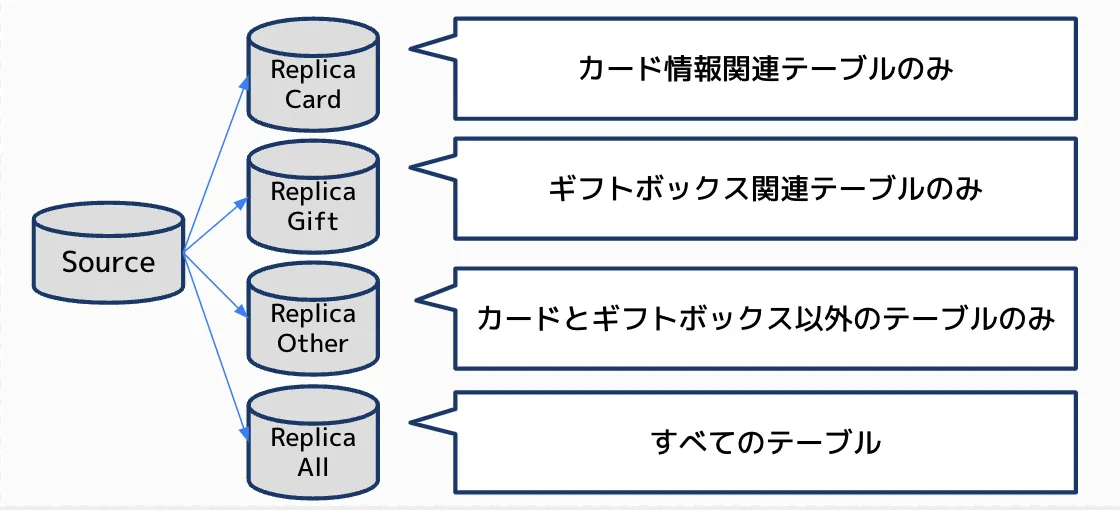
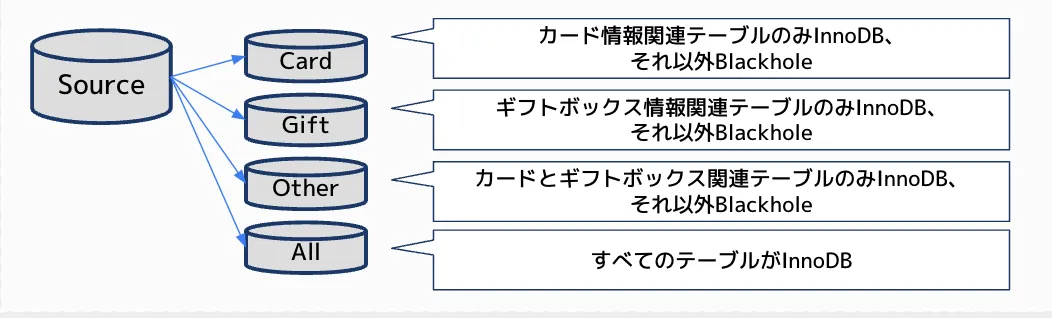
Cardグループにはカード情報関連のテーブルのみレプリケートし、
Giftグループにはギフトボックス関連テーブルのみレプリケート、
Otherグループには、カード情報関連とギフトボックス関連以外のテーブルのみレプリケート、
Allグループはすべてのテーブルをレプリケートするが、アプリケーションからは参照させない。
という構成です。
このフィルタリング構成をとることで、レプリカDB側が送られてきた更新クエリを適用する範囲がグループごとに絞られるので、レプリケーションの遅延を解消することができ、高負荷状態のイベントを乗り切ることができました。
しかし、このフィルター導入によるフィルタリングは以下のデメリットがありました。
- MySQL MHAを利用した冗長化ができない
- サーバー費用が余計にかかる
レプリケーションフィルタリングによる変則レプリケーションではMySQL MHAを利用した冗長化ができない
MySQL MHAは昔からよく利用されている、MySQLを冗長化してくれるサードパーティのツールです。 ソースDBがダウンしたときに、データの不整合を防ぎながらフェイルオーバーを実現できる機能をもっています。
このMySQL MHAはフィルタリング機能を用いた変則レプリケーションの環境では利用することができません。
MySQL MHAではすべてのレプリカDBが同じフィルタリングルールである必要がある為です。
異なるフィルタリングルールがレプリカ上に存在している状態で、MHAを起動しようとすると下記のようなエラーが出力され起動できません。
[error] Replication filtering check failed
All slaves must have same replication filtering rules.
Check SHOW SLAVE STATUS output and set my.cnf correctly.
[warning] Bad Binlog/Replication filtering rules:そのためMHAを利用した即時フェイルオーバー可能な冗長構成をとることができませんでした。
MHA未利用の状態で、ソースDBがダウンした際にレプリカのAllグループ(全テーブルレプリケートしてるグループ)を手動で昇格させても、レプリケーションがエラーで停止する可能性が非常に高いです。
なぜなら、レプリケーションは非同期レプリケーションの為、新ソースDBであるAllグループと他のレプリカグループ間でデータが揃っている保証がないからです。
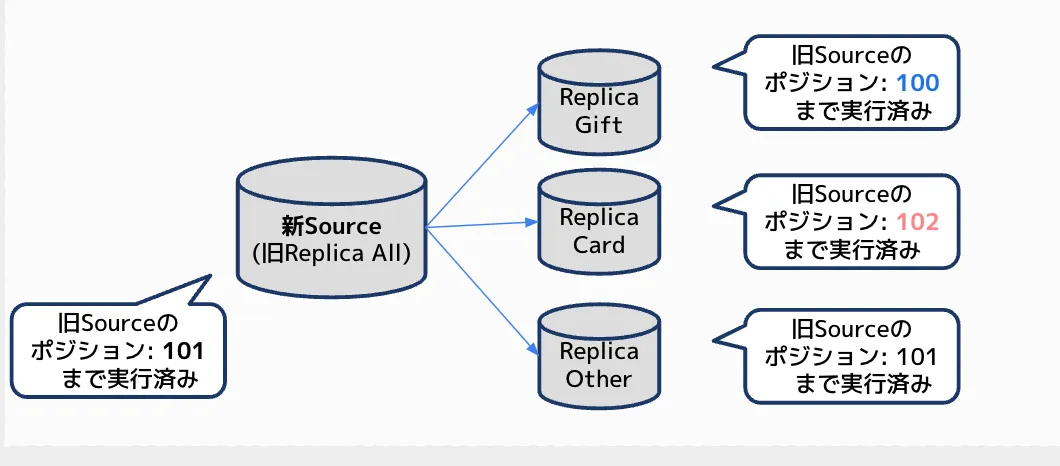
この例図では新ソースではポジション101まで実行済みのデータとなっていますが、
Giftグループのレプリカではポジション100まで、Cardグループはポジション102のように、
それぞれがどこまでデータに反映済みかが異なってくるため、 この状態でレプリケーションを再開しても、ソースとレプリカ間でデータが不整合な状態となってしまう可能性が高いです。
データを全台で揃えるためには、新ソースとなるDBデータをコピー元として全レプリカにデータをコピーしなおしてレプリケーションを再構築する必要があります。
しかし、GFではすでにDBのデータサイズが数百GBを超えており、全レプリカへのデータコピーしなおすだけで半日以上はかかる想定となっていました。
その間ゲームは長時間のメンテナンス状態にする必要があり、ユーザーへの影響は非常に大きいものとなってしまいます。 ですので、長時間のメンテナンスが必要なデータ転送を避ける方法を考える必要がありました。
レプリケーションフィルタリングによる変則レプリケーションではサーバーコストが余計にかかる
データ転送を避ける方法として採用したのが、待機系のレプリカを用いた多段レプリケーションの構成です。
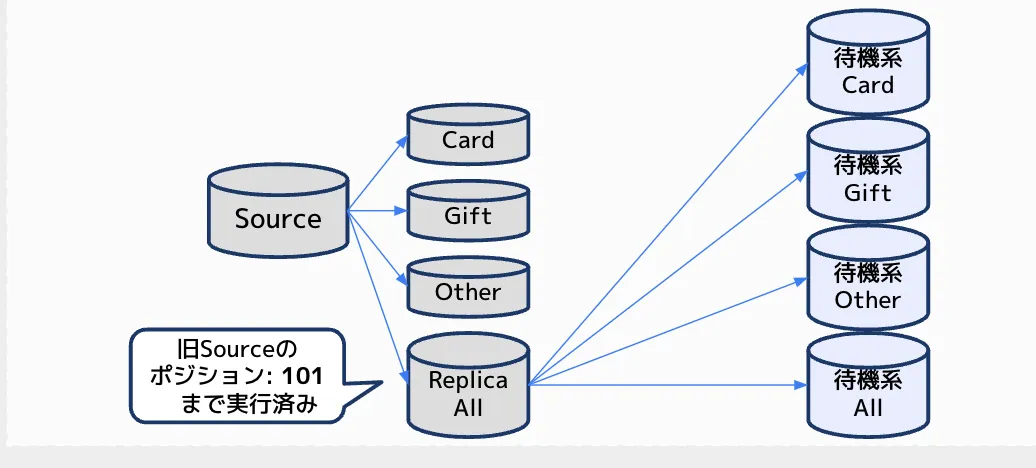
この構成でソースDBがダウンしても、次期ソースであるAllグループと、その配下にいる待機系のレプリカグループのレプリケーションは維持されるので、待機系のレプリケーションのデータがずれることはありません。
ソースDBがダウンしたときは、アプリケーションのDB向き先を次期ソースであるAllグループと待機系のレプリカに変更することで対応完了とすることができます。 これにより、半日以上かかる見込みのダウンタイムを回避することができました。
しかし、この多段レプリケーションの構成では普段使わない待機系のレプリカを常に維持しつづけないといけないため、 通常の2倍のサーバー台数を用意しないといけないことになります。
しばらくこの構成で運用をつづけていましたが、待機系のDBが必要ない方法を検討していました。
Blackhole Storage Engineを利用した変則レプリケーション
そこで採用したのがBlackhole Storage Engineを利用した変則レプリケーションです。
Blackhole Storage EngineはMySQLのストレージエンジンの一種です。
このストレージエンジンが指定されているテーブルは更新クエリを受け付けますが、実際にはデータは破棄して何も格納しません。
つまり、フィルタリング機能をつかったときと同じルールでレプリカのテーブルごとにストレージエンジンを変更することで、フィルタリング機能と同様に更新処理の分散が可能となります。
Blackhole Storage Engineを導入することの最大のメリットは、MySQL MHAによる冗長構成を組めることです。
MySQLのフィルタリング機能の設定は不要になるので、MHAを利用することが可能です。
MHAの設定でno_master=1を指定したサーバーは昇格候補から除外されるので、Allグループのレプリカ以外はこのno_master設定を有効化し昇格候補から除外しておきます。
既存のInnoDBストレージエンジンのテーブルをブラックホール化するには、ALTER文でテーブルのストレージエンジン指定を変更します。
テーブルに外部キー制約があるとブラックホール化できないなどいくつかの条件があるので、その際は一度DROP TABLEして定義を変更してテーブル作成しなおすなどの対応が必要になります。
ブラックホール運用による課題
このブラックホールを利用した変則レプリケーションで数年間運用を続けていましたが、下記のような課題や事故が発生していました。
- 新規テーブル追加時は都度ReplicaのグループごとにBlackhole化が必要
- ソースDBでテーブル定義変更のクエリを実行した際、エラーでレプリケーションが停止する事故
- データベースの復旧手順が複雑で属人化
新規テーブル追加時は都度ReplicaのグループごとにBlackhole化が必要
機能追加などでテーブルが新規に追加になるたびに、都度レプリカグループごとにブラックホール化の作業が必要となります。 テーブルをソースDBに追加すると、レプリカでも当然InnoDBでテーブルが作成されます。
そのテーブルがどのレプリカグループがデータの実体をもっていればいいのかを判断し、都度適切なレプリカグループでブラックホール化の作業をしなければなりません。
ソースDBでテーブル定義変更のクエリを実行した際、エラーでレプリケーションが停止する事故
ブラックホール化するテーブルに外部キー制約がついていた場合、レプリカDB側では一度DROP TABLEして定義変更して作成しなおしています。 つまり、ソースDBとレプリカDB間でストレージエンジン以外にもテーブル定義が異なる状態ということです。
この状態で、アプリケーションの仕様変更などの理由でテーブル定義の変更をソースDB側で実行しようとすると、レプリカDB上にはその定義が存在しなかった場合、 エラーとなりレプリケーションが停止してしまうという事故が何度が発生しました。
データベースの復旧手順が複雑で属人化
バックアップからデータをリストアするとき、通常のレプリケーションであればバックアップからデータをもってきてレプリケーションを再構築して完了ですが、
ブラックホール構成の場合、バックアップからデータを持ってきた後、レプリカグループごとにルールに沿ってテーブルをブラックホール化するという作業が必要です。
復旧手順自体はドキュメント化してありましたが、実際にブラックホール化するルールや手順を把握しているのは私一人の状態で完全に属人化していました。
現在のデータベースの状態
現在ではこのブラックホールの運用をやめ、通常のシンプルなレプリケーションに戻しています。 これによって先程あげた課題を解消することができました。
実はブラックホール運用をやめて元の構成に戻すためには様々な苦労があったのですが、
これについては3/7(木)開催のCyberAgent Game Conference 2024の以下のセッションでお話しますので、ぜひご視聴いただければと思います。
CAGC2024 12年目を迎えた『ガールフレンド(仮)』におけるデータベースの負債解消への道のり
まとめ
MySQLにはレプリケーションフィルタリングという機能があり、レプリカの負荷を分散することができます。
Blackhole Storage Engineをつかうことで、レプリケーションフィルタリング機能をつかわなくても同様の効果が得られます。
しかし、どちらの方法にも運用上の課題があるので注意が必要です。 やむを得ない事情で使用する際は、事前にしっかり検証をしましょう。
