はじめに
株式会社QualiArtsで「IDOLY PRIDE(以降、アイプラ)」のバックエンドエンジニアチームのリーダーをしている末吉です。 主にゲームAPIの開発やインフラの運用、チームメンバーの進捗管理や開発スケジュールの策定等を担当しています。
アイプラは2021年6月にリリースされ、今年の6月に2周年を迎えました。 データウェアハウスにGoogle CloudのBigQueryを使用しており、2年間その運用を支えてきました。

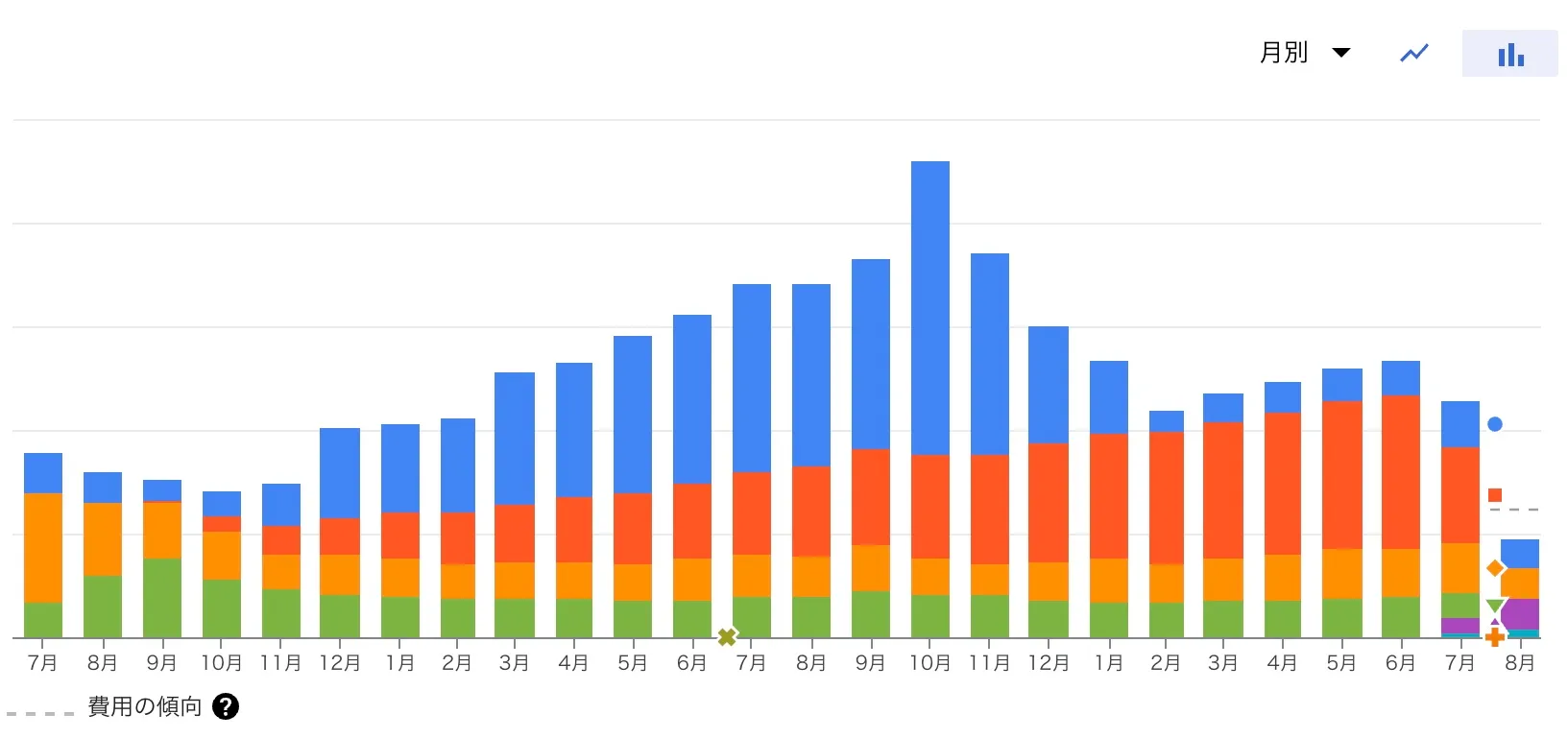
しかし、運用をしていく中で1つの課題が出てきました。それがBigQueryにかかる料金の肥大化です。
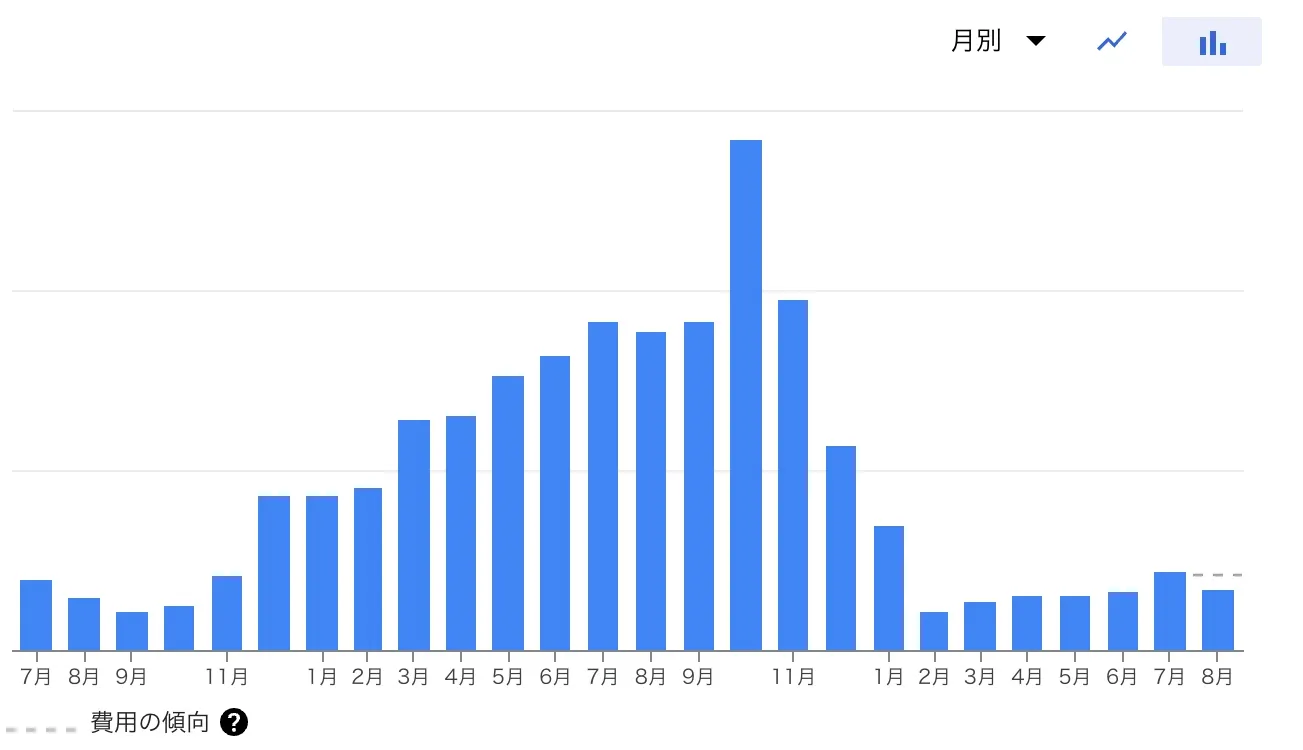
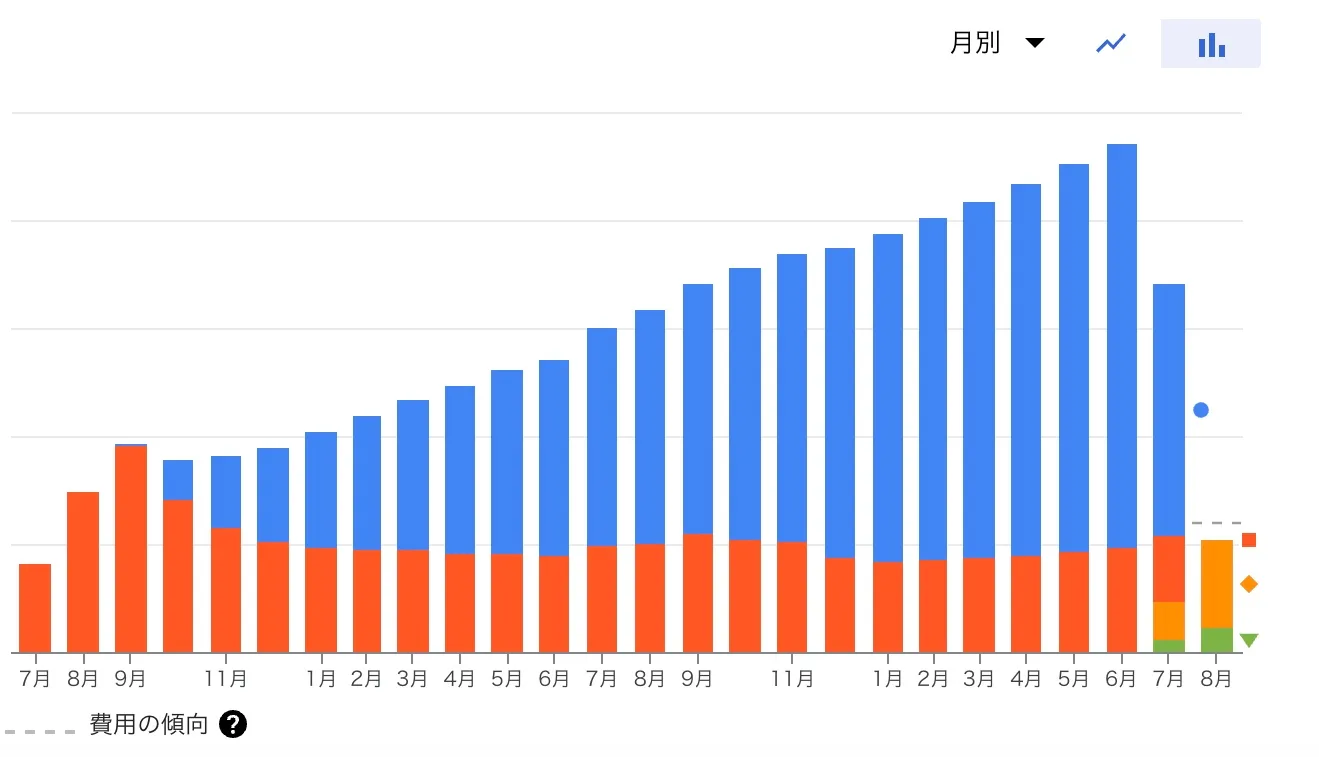
リリース当初はそこまで問題にはなっていなかったのですが、1年間半ほどの運用で約2.5倍ほどの料金がかかるようになっていました。
そこで、2022年10月頃からBigQueryの料金削減に取り組むことにしました。
結果的に本記事の執筆時である2023年8月時点では、料金をリリース時よりも低い水準まで削減することができました。
本記事ではどのようにBigQueryの料金を削減したのかを紹介できたらと思います。 (補足になりますが、記事内で紹介しているクラウドインフラ利用料金は2023年08月時点のものです。)
アイプラのBigQuery
アイプラではBigQueryに下記のようなデータを保存しています。
- 「ユーザーがいつどういうアイテムを獲得したか」などのユーザー行動ログ
- APIアクセスのリクエスト情報やレスポンス情報をまとめたアクセスログ
これらのデータはリリース機能に対するユーザーの動向調査で使われたり、お問い合わせによって発覚した不具合の原因調査などで使われたりしています。
プランナーやアナリストなど、エンジニア以外の職種もBigQueryを使用しており、日々の運用に欠かせないサービスとなっています。
また、BigQueryをデータウェアハウスとして選択したことで、下記のような恩恵を享受しています。
- TBやPB規模のデータでもクエリの結果を即座に返却してくれるパフォーマンス性
- 完全サーバーレスによる管理コストの低下
運用による料金の増加
そんなBigQueryですが、冒頭で記載した通り運用をしていく中で少しずつ料金が肥大化していました。
中でも、下記の2つが料金の大半を占めていました。
分析料金
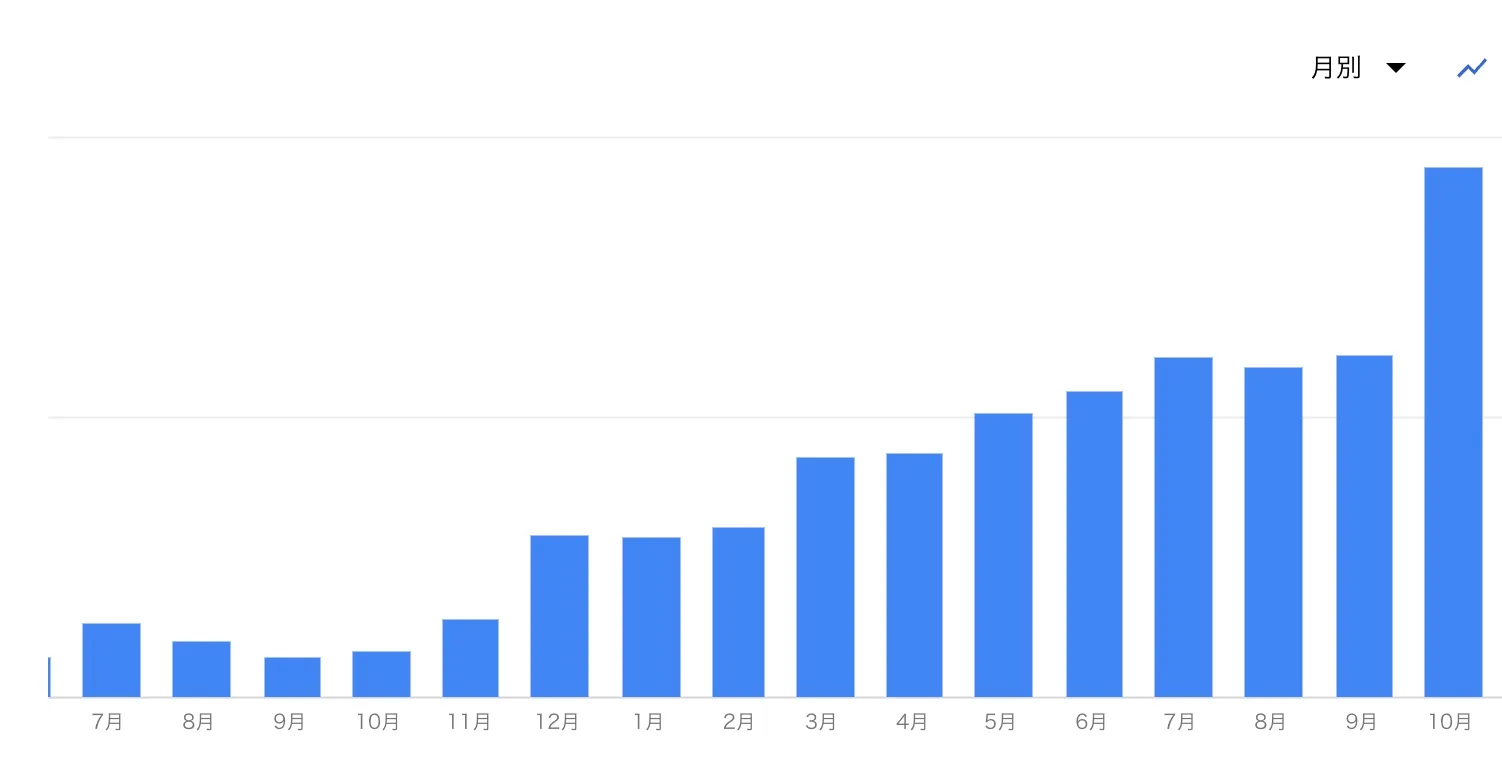
まず1つ目に、分析料金がリリース当時に比べて上がっていました。
こちらは文字通り、BigQueryに対して実行したクエリの処理にかかる費用です。 スキャンするサイズによって料金が変動します。 東京リージョンの場合、約1TBごとに$6ほどかかります。
ストレージ料金
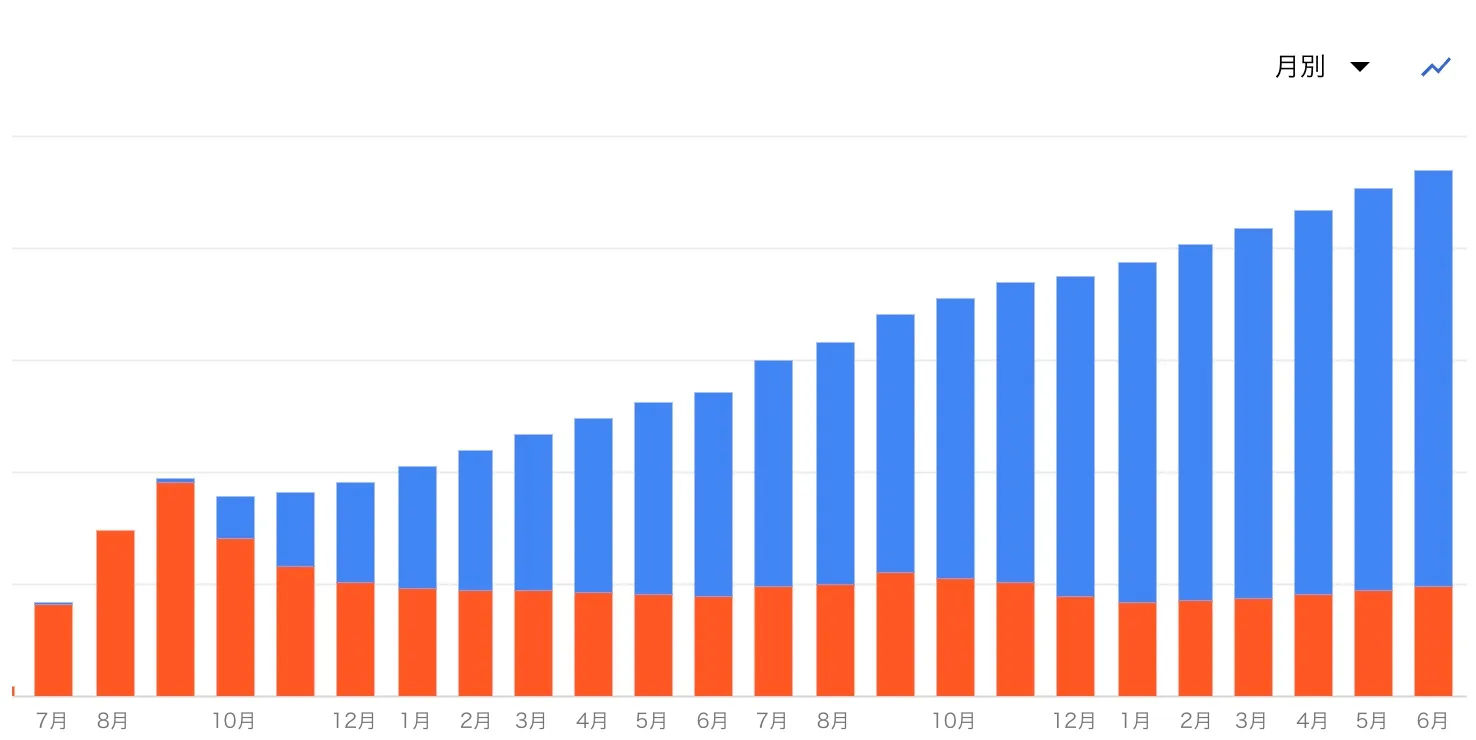
2つ目に、ストレージ料金も上がっていました。
こちらも文字通り、BigQueryにデータを保存する費用です。ストレージ料金にはアクティブストレージとロングタームストレージと呼ばれる2種類の課金体系があります。
アクティブストレージは、過去90日間で変更されたテーブルやパーティションが含まれます。 東京リージョンの場合、約1TBを1ヶ月保存すると約$23ほどかかります。
ロングタームストレージは、 90日間連続して変更されていないテーブルやパーティションが含まれます。 東京リージョンの場合、約1TBを1ヶ月保存すると約$16ほどかかります。
料金を削減するために行ったこと
このように、BigQueryの分析料金及びストレージ料金が徐々に上がっていました。放置しておくとどんどん増えていってしまうので、長期運用をしていく上では重要な課題でした。
そこで、BigQueryの料金を削減するために下記のことを行いました。
スキャンサイズの大きいクエリを特定&改善し、分析料金を削減した
分析料金についてですが、まずはスキャンサイズの大きいクエリを特定することが大事だと考えました。
しかし、闇雲にコンソールから履歴を遡ってスキャンサイズの大きいクエリを抽出するのは現実的ではありません。 冒頭で述べたように、エンジニアだけではなく他の職種も毎日BigQueryでクエリを叩いているので、クエリの数が非常に多いからです。
そこでBigQueryのINFORMATION_SCHEMAテーブルを利用することにしました。
INFORMATION_SCHEMAテーブルは、
- 各テーブルが作成がされた日時
- 各テーブルの行数
- テーブルの各列の名前とデータ型
など、所謂BigQueryのメタデータを格納しているテーブルになります。 その中にJOBS_BY_PROJECTというテーブルがあり、こちらにはプロジェクト内のクエリ実行履歴が格納されています。
下記のようなクエリを作成し、その月に実行されたクエリの中でスキャンサイズの大きい物を抽出しました。
SELECT
DATETIME(creation_time, 'Asia/Tokyo') AS creation_time,
job_id,
user_email,
query,
total_bytes_processed / 1024 / 1024 / 1024 AS use_GB,
FROM
`プロジェクト名`.`region-リージョン名`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
TIMESTAMP('2022-10-01 00:00:00','Asia/Tokyo') <= creation_time
AND creation_time < TIMESTAMP('2022-11-01 00:00:00','Asia/Tokyo')
ORDER BY
total_bytes_processed DESC
LIMIT 200その結果、定期的に実行されているクエリの中でスキャンサイズの大きいものを複数特定することができました。 中にはエンジニア以外のセクションの方が実行しているクエリがあったので、そのセクションの担当者と協力する形でクエリの改善を行っていきました。
具体的に改善したクエリの一例として、下記のようなクエリがありました。
SELECT
jp_date,
user_id
FROM
`テーブル名`
WHERE
jp_date <= CURRENT_DATE('Asia/Tokyo')このクエリの場合、開始時刻がWhere句で指定されていないので、サービス開始時の日時~クエリ実行時の日時の範囲でクエリが実行されます。 その為、運用が長くなればなるほどスキャンサイズも比例して大きくなっていきます。
こちらは以下のようにWhere句で開始時刻を指定することにより、スキャンサイズを大幅に削減することができました。
SELECT
jp_date,
user_id
FROM
`テーブル名`
WHERE
jp_date BETWEEN DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)
AND CURRNET_DATE('Asia/Tokyo')課金モデルを移行することにより、ストレージ料金を削減した
ストレージ料金の削減方法について調べていたところ、2023年7月にCompressedStorageという課金モデルがGAになったことを知りました。
従来の課金モデルであるLogicalStorageでは、「非圧縮」状態のデータ量に対して費用が発生していました。 それに対して、こちらのCompressedStorageでは「圧縮」状態のデータ量に対して費用が発生します。
その為、圧縮率が高ければストレージ料金が削減できると考えました。
CompressedStorageには手動で下記のクエリを実行して移行を行いました。
ALTER SCHEMA DATASET_NAME
SET OPTIONS(storage_billing_model = 'physical');1つ注意があり、CompressedStorageはLogicalStorageに比べて1GBあたりの単価が高くなります。
下記は2023年8月時点での東京リージョンのストレージ料金です。こちらを見て分かる通り、圧縮率が低い場合は逆に料金が高くなってしまいます。
| アクティブストレージ | ロングタームストレージ | |
|---|---|---|
| LogicalStorage | $0.023 per GiB | $0.016 per GiB |
| CompressedStorage | $0.052 per GiB | $0.026 per GiB |
その為、データセット単位で圧縮率を確認した上で、圧縮率が高く費用削減の効果が見込めるデータセットのみ移行を行うことが大切です。
INFORMATION_SCHEMAのTABLE_STORAGE_BY_PROJECTテーブルに対して下記のようなクエリを叩くことにより、データセットごとの圧縮率を確認することができます。
SELECT
project_id,
table_schema as dataset,
ROUND(SUM(total_logical_bytes)/SUM(total_physical_bytes),2) AS compressibility
FROM
`プロジェクト名`.`region-リージョン名`.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT
GROUP BY
project_id,
table_schema
HAVING
SUM(total_logical_bytes) > 0おわりに
本記事では、運用をしていく中で上昇していたBigQueryの料金を削減するために行ったことを紹介させていただきました。
INFORMATION_SCHEMAを利用したスキャンサイズの大きいクエリの抽出や、ストレージ課金モデルの移行等を行うことにより、分析料金及びストレージ料金を合わせて約70%の削減することができました。
本記事が皆さまの運用に少しでもお役に立てば幸いです。
