はじめに
株式会社QualiArtsのTA室でUnityエンジニアをしています、渡邉です。
2021年6月リリースの「IDOLY PRIDE」(以降、アイプラ)は次世代のグラフィックを目指しMetal, Vulkanを前提とした最適化を行っています。
本記事では、その際に使用した新しい機能についての一部を紹介します。
参考用のライブ動画はこちらになります。解像度が高いこと以外は全て実機の処理と同じものが使用されているので一度見ていただくとより分かりやすいかと思います。
本記事は CA.unity #2 で発表したものに一部追記をして書いております。また、用語や基本的な説明は省略しているためそこはご了承ください。
実行環境
Unity
現在リリース済みのアイプラはUnity2020.3.4を使用しています。
Unity2019辺りから様々な高速化処理が実装されているのですが、バグが多く、リリースに使えない状態でした。
そのため開発中は常に最新を追うようにしており、2020.3LTSから現実的に使用できるようになったので、このバージョンの採用に至りました。(2020年までは様々な問題があり採用できるか不安な状態が続きました)
しかし、このバージョンも不安定な箇所があるため随時アップデートを行う予定となっています。
最新のUnityを使用すると様々な恩恵が受けられますが、常にバグと隣り合わせになることに注意が必要です。 (リリースノートのチェックは必ずしましょう)
RenderingPipeline
レンダリングパイプラインにはUniversalRenderPipeline(URP)10.5.0を使用しています。以前はLightweightRenderPipeline(LWRP) と呼ばれていたものですがGUIDは同じなので簡単に移行できます。Legacyパイプラインも使用できますが、CommandBufferの追加が非常に面倒でカメラの扱いもかなり不便なため今後のプロジェクトは積極的にURPの採用をオススメします。 開発中は Graphics リポジトリをフォークして常にコミットをチェックしていましたが、 今年に入ってからいろいろとありmasterブランチ以外は見えなくなった *1 のでこの手法は難しいかもしれません。
*1 10.x.xまで見れるが11.x.x以降が存在しない ≒ Unity2020.3までしかブランチを追えないLightmap
背景のライトマップは Progressive GPU Lightmapper
を使用していて、高性能なGPUベイクマシンを用意することで高速なベイクイテレーションを回すことが出来るようになりました。
CPUで実行すると数時間かかるベイク処理が数分で終わるため是非とも使いたい機能ですが、2020.3になるまでは様々なバグに悩まされました。
現在もたまにフリーズしますが、いろいろと工夫することでギリギリ製品に使用できるレベルになっているかと思います。
これまでのプロジェクトはDCCツール上でベイクしていたためライトの扱いが不便でしたが、全てをUnity上で完結させることで最大効率で描画も出来るようになりました。

レンダリング
レンダリングにはポストエフェクト含め全てHDRで処理を行い、背景には物理ベースレンダリング(PBR)を用いています。
対象プラットフォームは以下になります。
- Android → Vulkan or OpenGLES3.1以降
- iOS → Metal GPUfamily3以降
この後の項で紹介しますが、新しめな機能を使用するとOpenGLESの場合、挙動が不安定になることがあるためモバイルではVulkanを前提にする必要があります。 安定動作は4〜5年前に発売されたハイエンドから2,3年前のミドルレンジをターゲットにしています。
ここまでで分かるように描画周りは最新のUnityの機能をフル活用しており、かなり攻めた状態でリリースできたかな思っています。
Render Pipeline
Scriptable Render Pipeline
ScriptableRenderPipeline はUnityが新しく用意している描画カスタマイズシステムで、 モバイルプラットフォームでは UniversalRenderPipeline(以下URP) が用意されています。
ScriptableRenderPipelineにはRendererFeatureという概念があり、簡単にCommandBufferを追加できるようになっています。 以前はカメラに直接CommandBufferを追加する方式だったので管理が難しかったのですが、この機能により最適化も行いやすくなりました。
アイプラではこのRendererFeatureを10個追加することで描画と処理の最適化を行っています。
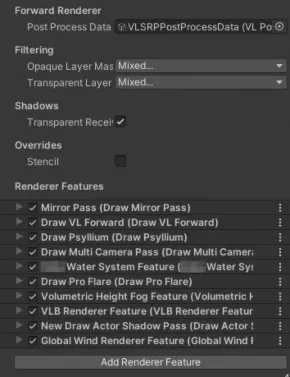
URPでポストエフェクトを追加しようとした場合RendererFeatureを使うことになると思いますが、既存のポストエフェクトの外に追加することになるため無駄な処理が発生してしまいます。
そこでURPで提供されているPostProcessPassとForwardRendererクラスを使用せず、これらを複製した独自クラスを用意することにより必要な処理を自由に追加できるようにしました。
これによりポストエフェクトも自由にカスタマイズ出来ますし、処理の流れを完全に理解出来るようになるのでおすすめな手法です。
ScriptableRenderPipelineはリリースされてからかなり経っており、現在であれば様々なサンプルも見つけられると思います。また、実装が一部を除いて公開されているので一通り読むのが一番理解しやすいのでおすすめです。
ShaderGraph
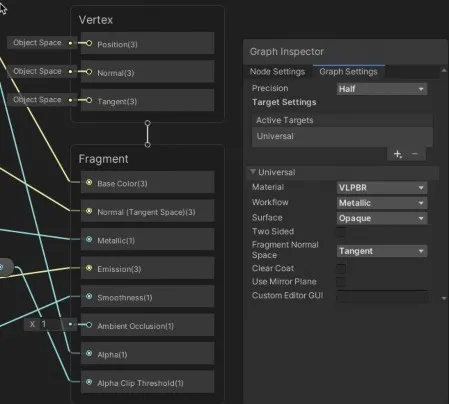
背景には全て物理ベースレンダリングを採用しており、シェーダは ShaderGraph を使用しています。
ノードベースで簡単にシェーダが作成でき、後述する SRPBatch や最適化が自動で適用されるので非常に便利です。 しかし、一部効率の悪い処理が入る可能性があるので生成コードを一度読むといいかと思います。
ShaderGraphは Target という概念があり (旧MasterNode)、このクラスがコードの生成を行っています。URPでは UniversalTarget
というクラスが用意されているのでそれを拡張したTargetクラスを実装しています。
Unity2019まではこの処理が拡張しにくい設計でしたが、Unity2020で刷新されほぼ全ての処理に介入できるようになり実用的になっています。
Unity2021ではさらに非効率だった設計が改修されており完成形が見えてきた気がします。
ShaderGraphに関しても、Unityのアップデートのたびにかなり仕様が変わっています…
Legacyからアップグレードする機能はありますが、カスタマイズした際のバージョン間の互換は全く無いので Target を追加する場合は覚悟が必要かと思います。
SRPBatch
SRPBatch
とはScriptableRenderPipelineのメイン機能とも言える新しいバッチシステムです。 モバイルではMetal又はVulkanが対応しており、 SetPass (テクスチャやシェーダの切り替え)を最小限にして DrawCall の発行効率を最大化してくれます。
これによりCPUの描画負荷を1.5倍から2倍程度高速化することができます。 アイプラではほぼすべてのシェーダをSRPBatchに対応させることで可能な限りバッチされるようになっています。

SRPBatchの機能を切り替えた際の結果が上記画像で左がSRPBatchオフ、右がSRPBatchオンになっています。
SetPass callsが 283 から 155 に減少しており、完全に比例するわけでは無いですがCPU負荷もこれに伴って1.5倍から2倍程度高速化されています。
ただし、適用には様々な条件があり単純に対応するだけだとあまりバッチされない… みたいなことになるのでMaterialの管理を工夫したりする必要はあります。また、GPUの負荷が減るわけではないのでそこも注意が必要です。
割と最近まで不安定だったので使用する場合はUnity2020.3以降がオススメです。
描画API
本項ではUnityの新機能というわけでは無いですがMetal,Vulkan世代をターゲットとしたことにより使用できるようになったAPIを紹介します。
軽量化するには?
まず軽量化のフローを紹介します。
開発者の方は実感していると思いますが複数のGameObjectで数値計算等を行うとC#はかなり遅く、TransformのようなUnityAPIと組み合わせると更に遅くなります。
低スペックモバイルでの実機検証時の体感ですが、100個くらいのオブジェクトに対して直列処理すると無視できない負荷となってきます。
そこで便利なのが C# Job System です。
機能が公開されてからかなり経っているので既に活用されている方も多いと思いますが、簡単に言うとC#の実装方法に制限を掛けることによりマルチスレッドで高速な
実行が可能になる機能です。また、更に制限を掛けて実行する Burst
に対応させることで、さらなる高速化が見込めます。
Transformに関しても高速アクセスが可能になる IJobParallelForTransform
と組み合わせると想像を遥かに超えた速度で並列処理が行なえます。 このように、一定の負荷があり、C# Job Systemで実装可能な処理であれば基本的にBurstで実装したほうがいいです。
そして、さらに早いのが ComputeShader です。
ComputeShaderはGPUの並列処理を有効活用し、メッシュやMaterialが必要な通常のシェーダとは異なり、数値計算を行うシェーダで入力と出力にComputeBufferというものを使用します。
そのComputeBufferを頂点シェーダに渡すことで描画にも影響を与えられるようになっています。
ただし、頂点シェーダとの受け渡しをするためには Shader Storage Buffer Object (SSBO)
にGPUが対応している必要があります。Vulkanであれば対応されていますがOpenGLESの場合はSoCによってサポート外のものがあったので実質Vulkan専用の機能になります。
UnityでSSBOの対応を調べるには SystemInfo.maxComputeBufferInputsVertex を見るといいですが、Androidの端末によって謎の値が返ってくることがあり信用できません…
実装方法が少し特殊ですが対応自体は簡単なのでVulkan世代の端末には積極的に使っていきたいところです。(環境依存を吸収してくれるUnityに感謝)
ここからは各種APIの活用例を紹介します。
レンズフレア
レンズフレアの処理ですがアイプラでは ProFlare
というアセットを使用しています。 これは、URP10.5.0*2 にはレンズフレアの処理が無いため何かしらの実装が必要となってしまっているためです。
このアセットはパフォーマンスの良さを謳っていますが、100個近い数を置くと頂点更新処理と描画処理でGPU,CPU共に高負荷となりモバイルでは動作しませんでした。(
そこまで置くことを想定していない気がしますが…)
そこで、描画・頂点更新処理をほぼ全て書き換えパフォーマンス改善を行いました。
処理フローはこちらです↓

ComputeShaderは数値計算に特化していますが、GPU処理なのでTextureの読み込みも可能です。これにより遮蔽判定をDepthTextureで行えるため、Raycast負荷を0にすることが出来ました。
この結果を元に DrawProcedural を用いて描画しています。
public void DrawProcedural (GraphicsBuffer indexBuffer, Matrix4x4 matrix, Material material, int shaderPass, MeshTopology topology, int indexCount, int instanceCount, MaterialPropertyBlock properties);このAPIはRendererやMeshが不要で、頂点のつなぎ方を GraphicsBuffer で指定し、 indexCount と instanceCount を指定することで動的に描画を制御することが出来ます。 頂点シェーダの一部を参考に載せておきます
// C#上ではComputeBuffer
StructuredBuffer<ProFlareProcessData> _ProcessBuffer;
StructuredBuffer<ProFlareElementData> _ElementBuffer;
struct Varyings
{
float4 positionCS : SV_POSITION;
half2 uv : TEXCOORD0;
half4 color : COLOR;
};
// 頂点入力はVertexIDのみ
Varyings Vertex (uint id : SV_VertexID)
{
Varyings output = (Varyings)0;
// QuadなのでビットシフトすればElementID
ProFlareElementData elementData = _ElementBuffer[id >> 2];
ProFlareProcessData flare = _ProcessBuffer[elementData.flareIndex];
...
ComputeBufferは配列のようにアクセスできるので要素の切り替えが容易になり、毎フレーム変動するレンズフレアの負荷を最小限に抑えることができました。

このような想定以上に大量のFlareを置いたシーンでも9ms→1.6msまで削減できています。
極論、このAPIを使えば何でも出来るとも言えるので今後も活用したいと思っています。
*2 12.x.xはLensFlareの処理が追加されていましたボリュームライト
ライトのフォグには VolumetricLightBeam を使用しています。採用理由は、様々な角度から見ても破綻がなく標準でInstancing, SRPBatchといった高速化に対応していたためです。

上記画像の矢印の先にあるものがVolumetricLightBeamです。薄暗いライブ会場を彩るものとして必須なものとなっています。
しかし、アイプラでは100台近くライトが配置されておりモバイルで動かすには程遠い*3 ものとなっていたのでこちらのアセットも描画、更新処理をほぼ書き換えました。 この原因となっているのがCullingとMaterialPropertyBlockの更新です。
Culling
VolumetricLightBeamは OnPreCull
イベントを使用して処理の更新を行っているのですが、反射面の描画等で ScriptableRenderContext.Cull
を呼び出しているためその度に無駄に呼び出しが発生してしまいます。
そこでRendererを使用せずに自前でカリングすることで不要な処理が発生しないようにしました。これにより、初期化時のRenderer生成も0になったのでノーコストでVolumetricLightBeamの追加が可能になりました。
MaterialPropertyBlock
instancingで描画するため、シェーダの値の変更はMaterialPropertyBlockを使用しています。しかし、MaterialPropertyBlockを大量に更新するとCPUの負荷が跳ね上がってしまうためComputeBufferを通して値を送っています。 NativeArrayからComputeBufferへのコピーは SetComputeBufferData メソッドを呼び出すだけなので簡単です。
処理フローはこちらです↓
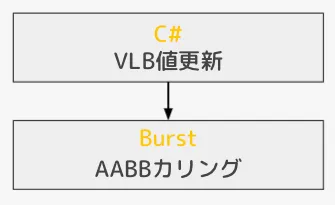
C#でComputeBufferの数値を更新し、AABBカリングの結果によりinstancingの数を変動させています。
描画には DrawMeshInstancedProcedural を使用します。
このAPIは指定Meshを指定回数分instancingして複製するだけのシンプルなメソッドです 引数にMaterialPropertyBlockがあるのでそこからComputeBufferを渡すことでシェーダで受け取ることが出来ます。
public void DrawMeshInstancedProcedural (Mesh mesh, int submeshIndex, Material material, int shaderPass, int count, MaterialPropertyBlock properties);観客(ペンライト)
観客はライブの重要な一要素なのでかなりこだわっており、ゲームの仕様上動員人数を一人単位で変動できるようにしています。 例えば3万人の箱に2000人だけ動員といったことを実現する必要がありました。 また、カメラに近い観客は立体感を出すために体も描画するようにしています。

これを可能にするのがComputeShaderで、観客一人ひとりの数値を管理することで個別で動作させられるようになりました。 身長や輝度、流すアニメーションも変えているのでリアルなライブ感がかなり再現できているかと思います。 座席データはMaya上のツールで配置が可能で優先度が振られているのでアリーナ席から順に人が入るといったことも可能です。
処理の流れは以下です↓

初期化時に座席データからComputeBufferを生成しておき、ComputeShaderではカリング、LookAt、数値更新を実行しています。 カリングは観客一人ひとり全てに対して行っていてカメラに写ったものだけを描画することで負荷を最小限にしています。
描画には DrawMeshInstancedIndirect を使用します。
このAPIは指定Meshを指定回数分instancingするだけですが、メソッドの引数で回数指定するのではなくIndirectBufferによって複製回数を指定します。
public void DrawMeshInstancedIndirect (Mesh mesh, int submeshIndex, Material material, int shaderPass, ComputeBuffer bufferWithArgs, int argsOffset, MaterialPropertyBlock properties);IndirectBufferはComputeBufferの ComputeBufferType を IndirectArguments で初期化したもので配列ルールは以下になります。
var args = new uint[5] { 0, 0, 0, 0, 0 };
var argsBuffer = new ComputeBuffer(1, args.Length * sizeof(uint), ComputeBufferType.IndirectArguments);
args[0] = (uint)instanceMesh.GetIndexCount(subMeshIndex);
args[1] = (uint)instanceCount;
args[2] = (uint)instanceMesh.GetIndexStart(subMeshIndex);
args[3] = (uint)instanceMesh.GetBaseVertex(subMeshIndex);
argsBuffer.SetData(args);上記は公式のリファレンスのサンプルでC#上で値を更新しているため一度配列に代入してからComputeBufferにコピーしていますが、ComputeShaderで更新する場合は以下のようになります。
RWStructuredBuffer<uint> _IndirectBuffer;
[numthreads(1,1,1)]
void CalcIndirect(uint3 id : SV_DispatchThreadID)
{
// カリング結果
uint size = _IndirectBuffer[0];
uint bodySize = _IndirectBuffer[1];
// ペンライトのInstancingサイズ
_IndirectBuffer[5] = (size >> 7u) + 1u;
// 体のInstancingサイズ
_IndirectBuffer[10] = (bodySize >> 4u) + 1u;
}
便利なことに DrawMeshInstancedIndirect にはIndirectBufferの byteOffset も指定できるのでカリング結果と複数のIndirect情報を一つのComputeBufferに格納しています。 ぱっと見では分かりにくいですがカリング結果をビットシフトすることでinstancing回数に変換して上書きしています。 ComputeShaderではいかに少ないビット数と計算処理で実装するかが肝なので考えるのは楽しいです。
まとめ
ただの機能紹介にはなってしまいましたが、Vulkan世代をベースにすることで今まで出来なかった様々な最適化が可能となりました。
また、Burstコンパイルを活用することでC#遅い問題はかなり解決できます。 欠点としてクラスが使えない*4
のでデータ構造の工夫が必要なのとdelegateのような便利系もない*5 ので使用箇所が絞られれてしまうのが残念です。
ComputeShaderは試しに何かを実装してみると分かりますがとにかく爆速です。
しかし、実装していく上でAndroidは過信してはいけないことが分かりました。 GeekBench5のMetal,Vulkan Computeベンチマークの結果が以下になります。
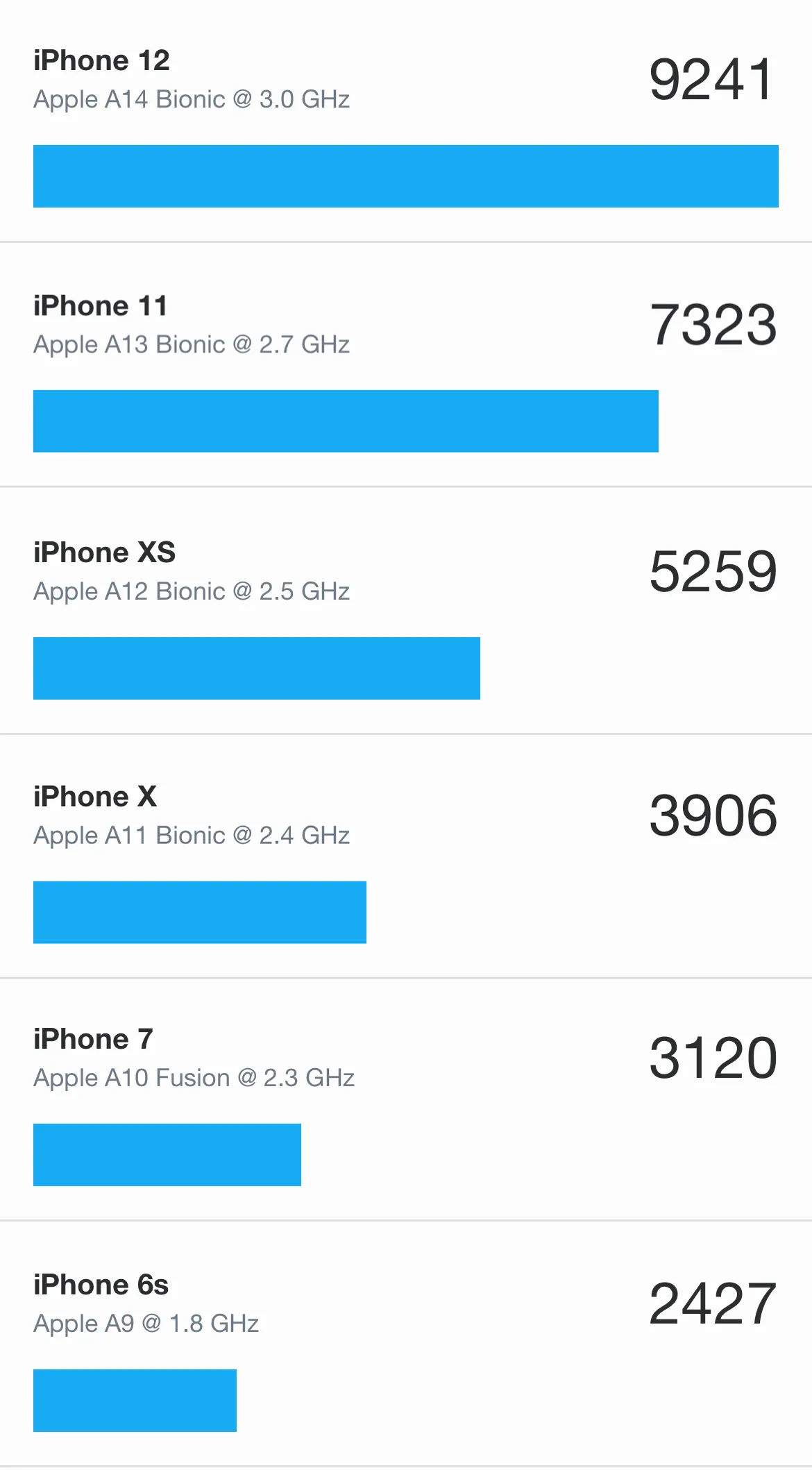
数値が高いほどComputeの性能が高いことを表しています。
実行環境が違うので一概には言えないですが、AppleAシリーズとSnapdragonには性能に大きな差がありました。
最初にiPhone6Sで動作確認をしていて高速だったため採用していた処理があったのですが、Androidで実行すると遅すぎて使い物にならず、試しにベンチマークを取ってみたらこの有様でした…
最新端末であるGalaxyS21も手元で試してみたところ 4565 だったので描画性能に比べComputeの性能は重要視されていない印象を受けました。
Computeは一般的なグラフィックスベンチマークでも表に出てこない箇所なのでそちらの数値と単純比較しないように注意が必要です。
本記事ではCPUの最適化に重点を置いていますが、超ローエンドのAndroid端末は現在も発売され続けているためどこまで担保するか、永遠の課題になりそうです。
*4 NativeArrayからポインタ取り出してアクセスするのが一番楽です
*5 Burst用の関数ポインタ機能は用意されていますが呼び出しがかなり遅くなるので恩恵が微妙になります(使い方間違ってるのかも…?)
